ControlAudio:清华团队实现音频生成的时间与内容精准控制 文本到音频生成技术正经历深刻
文本到音频生成技术正经历深刻变革。早期系统仅能合成简单音效,如今基于扩散模型的方案,已能根据“林间鸟鸣”等复杂描述,生成高度逼真的声景。这为影视、游戏及数字内容创作开辟了全新可能。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
然而,生成质量仅是基础,精确控制能力才是专业应用的关键。现有技术普遍面临两大瓶颈:一是难以精准锚定声音事件的时序,例如将鸟鸣严格控制在第2至5秒;二是在生成包含人声的音频时,语音清晰度与可懂度往往不足。这如同赋予画家精湛技艺,却无法精确控制笔触的轨迹与形态。
针对这一核心挑战,清华大学研究团队提出了ControlAudio。该方法的核心在于,通过一套系统化的数据构建流程与渐进式扩散建模策略,在一个统一框架内实现对音频时序结构与语音内容的联合精细控制。简而言之,它让AI在生成声音时,既能精确计时,也能清晰“说话”。
该研究由清华大学博士生江宇轩主导,研究方向为生成模型与多模态学习,由朱军教授与窦维蓓教授共同指导。论文已被ACL 2026主会议接收并拟推荐为口头报告,体现了其前沿性与学术价值。

论文地址:https://arxiv.org/abs/2510.08878
效果试听:https://control-audio.github.io/Control-Audio
当前文本到音频系统在保真度上已取得长足进步。但要满足专业级应用需求,精细化控制能力成为必须突破的瓶颈,主要体现在两个维度:
精确时序控制:要求模型能根据“鸟儿在2至5秒间鸣叫”这类指令,将特定声音事件准确锚定在指定时间窗口内。
清晰语音生成:当提示包含“一名男子说:‘今天天气真好’”时,生成的语音不仅需具备人声特征,其内容更须清晰可辨。
实现上述控制面临根本性挑战。核心障碍在于数据稀缺——具备精确时间戳与语音转录文本的高质量音频数据极为有限。此外,现有方法多专注于单一问题,缺乏能协同处理时序与语音内容的统一框架。
ControlAudio通过三个环环相扣的模块破解这一难题:
数据构建与表征:采用“真实标注数据与仿真生成数据”相结合的策略,构建多层次训练集。关键创新在于设计了“结构化提示词”,将文本描述、时间边界、音素信息统一编码,使预训练文本编码器能直接解析复杂的控制信号。
渐进式模型训练:采用分阶段训练策略。模型首先在大规模文本-音频对数据上学习基础生成能力;随后引入时间标注进行微调,掌握事件时序控制;最后融合音素信息进行联合训练,精进清晰语音的生成技巧。
引导采样推理:在生成阶段贯彻“由粗到细”理念。扩散过程早期,主要依赖文本和时间条件引导,确定声音事件的整体布局;生成后期则增强音素条件的引导强度,用以细化与完善语音内容。这一过程模拟了人类从构思框架到填充细节的创作逻辑。
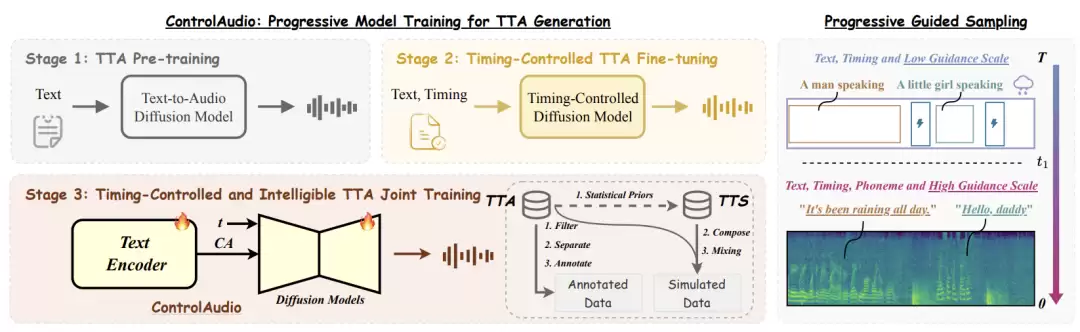
ControlAudio将多条件建模这一复杂任务,拆解为符合扩散模型特性的渐进式学习过程。
在训练中,模型分三步进阶:首先掌握“依据文本生成声音”;其次叠加“控制声音发生时间”的能力;最终习得“生成特定语音内容”的高级技能。通过使用“纯文本”、“文本+时间”、“文本+时间+音素”等不同组合的条件输入,模型对控制信号的理解得以逐步深化与精细化。

在推理阶段,对应的渐进式引导采样策略与之匹配。早期利用时间和文本条件搭建音频骨架,后期则用强音素条件雕琢语音细节。这种设计顺应了扩散模型自身的生成节奏,从而在时间对齐精度与语音清晰度上均获得提升。
为突破数据瓶颈,ControlAudio构建了一个多源混合数据体系,兼顾了真实数据的准确性与仿真数据的规模优势。
在真实数据方面,研究以带时间标注的AudioSet-SL数据集为基础,筛选含人声片段,通过语音分离与转写技术,获取“文本-时间-音素-音频”四位一体的细粒度数据。
为扩充数据规模,团队开发了大规模仿真数据生成流程:基于真实数据统计分析人声活动规律,依此合成单人或多人语音片段,按合理时间线排列并与背景音混合,构建出复杂的多事件音频场景。此举额外生成了超过17万条训练样本,显著提升了数据的多样性与复杂性。
此外,为提升模型对自然语言指令的理解,团队引入了基于思维链的自动解析流程,将“鸟儿在开头鸣叫,然后一个男人说‘你好’”这类描述,自动转化为“事件—时间—语音内容”的结构化格式,为模型提供精准可执行的输入指令。

在时间可控音频生成任务评测中,ControlAudio在衡量事件时间对齐的关键指标上显著优于现有方法。同时,在FAD(弗雷歇音频距离)、CLAP得分等整体音频质量指标上,也保持了竞争力乃至更优表现。

在包含语音生成的评测任务中,ControlAudio同样表现突出,生成的语音可懂度更高,整体音频质量更佳。这验证了其统一框架能有效协同处理时序控制与内容生成。

值得注意的是,ControlAudio在实现精细化控制的同时,并未牺牲其基础的文本到音频生成能力。在标准文生音频任务上,其性能与主流方法相当或更优,证明了其能力增强的有效性。

总体而言,ControlAudio从数据构建、模型训练到推理生成,系统性地推进了文本到音频的精细化控制。其核心贡献在于,首次在一个统一框架内实现了文本、时序与语音内容三者的协同建模,并在效果上超越了专注单一维度的既有方案。
这展现了更强的通用性与扩展潜力。随着多模态生成模型的发展,统一建模语音、音效与音乐已成为明确趋势。ControlAudio所实践的“多粒度条件统一建模结合渐进式生成”的技术路径,为通向通用音频生成系统提供了一条清晰且可扩展的解决方案。其目标在于推动AI从执行单一生成任务,迈向驾驭复杂、多维度要求的创造性内容生产。未来,创作者或能如同指挥家一般,精准调度AI生成的每一个声音元素。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。