OOM Killer:Linux内存耗尽时,它为何“错杀”了你的MySQL? 运维同事发来一条消息: “服务
运维同事发来一条消息:
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
“服务器上 MySQL 死了,但我看了一下内存占用,内存最多的明明是另一个 Ja va 进程,为什么 MySQL 被杀了?”
这背后,正是 Linux 内核中那位“冷酷”的 OOM Killer 在行动。
OOM Killer,全称 Out Of Memory Killer,是 Linux 内核在内存彻底耗尽时启动的“清道夫”机制。但它的行为逻辑,常常让人摸不着头脑——它并非随机挑选,也未必会挑中内存占用最大的那个“罪魁祸首”。它有一套自己的打分算法,其结果往往出人意料。
搞懂这套机制,不仅能解答“为什么是我的进程被杀了”的疑惑,更能让你掌握主动权,保护那些真正关键的服务不被误伤。

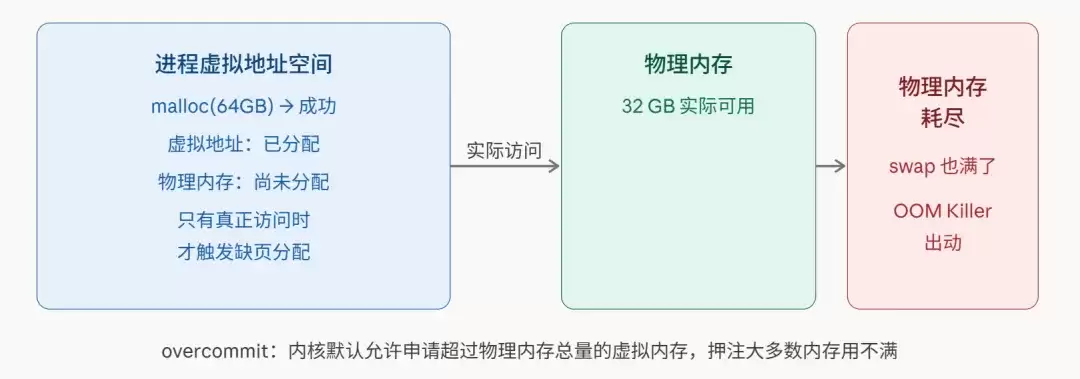
一个常被忽略的事实是:Linux 默认允许进程申请超过物理内存总量的内存。这种行为,被称为内存过度提交(overcommit)。
// 这行代码在 32GB 内存的机器上也能成功返回,不会报错
void *p = malloc(64LL * 1024 * 1024 * 1024); // 申请 64GB
// p != NULL,但实际上没有分配真实物理内存这里的malloc成功,仅仅是内核为你预留了虚拟地址空间。真正的物理内存分配,要等到你第一次访问这块内存时才会发生(也就是常说的缺页中断)。
内核打的算盘是:大多数情况下,进程申请的内存并不会被全部用满。这就像航空公司超售机票,赌的就是并非所有乘客都会登机。
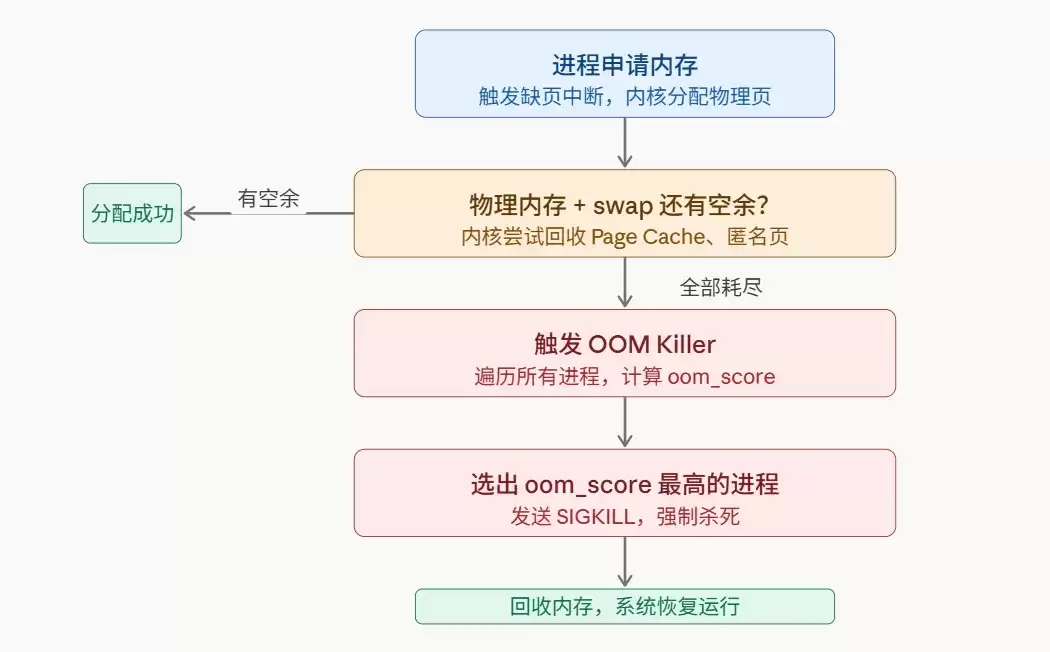
然而,一旦赌输了——所有进程都开始疯狂消耗内存,导致物理内存和交换空间(swap)全部告罄,内核就无路可退了。此时,只剩下最后的手段:杀掉一个或多个进程,回收内存。
顺便提一下,overcommit 的行为可以通过内核参数进行调控:
# 查看当前策略
cat /proc/sys/vm/overcommit_memory
# 0 = 启发式过度提交(默认)
# 1 = 始终允许,从不拒绝
# 2 = 严格模式,不允许超过阈值大多数服务器采用默认的 0,以追求更好的性能。而设置为 2 则最为保守,一旦申请内存超过阈值,malloc会直接失败,程序需要自行处理这种错误。
这是整个机制的核心,也是最容易产生误解的地方。
OOM Killer 的选择并非随机,也不单纯看内存大小。它会为每个进程计算一个oom_score,分数越高,“中奖”几率越大。
每个进程的得分都是透明的,可以直接查看:
# 查看某个进程的 oom_score
cat /proc/1234/oom_score
# 输出:342
# 查看管理员调整值
cat /proc/1234/oom_score_adj
# 范围 -1000 到 1000,-1000 表示永不被杀那么,oom_score 究竟怎么算?简单概括就是:进程占用的物理内存比例越高,基础分就越高,但这个分数会经过几个关键因素的加权调整。
核心影响因素包括:
正是这套复杂的加权算法,解释了为什么“内存占用最大的进程”未必是得分最高的那个。来看一个直观的对比:

从内存耗尽到进程被终结,内核内部走的是这样一条路径:
整个过程在内核日志中都有迹可循。因此,发生 OOM 后的第一件事,就是查看日志:
# 查看内核日志,找 OOM 事件
dmesg | grep -i “oom”
# 或者
dmesg | grep -i “killed process”
# 输出类似:
# [123456.789] Out of memory: Kill process 4521 (mysql) score 510 or sacrifice child
# [123456.790] Killed process 4521 (mysql) total-vm:8372228kB, anon-rss:7654321kB日志会清晰地告诉你:哪个进程被选中、它的 oom_score 是多少、以及它具体使用了多少内存。
理解了 oom_score 的机制,保护关键进程的方法就变得直接而有效。
# 把 MySQL 的 oom_score_adj 调成 -1000,内核永远不会主动杀它
echo -1000 > /proc/$(pidof mysqld)/oom_score_adj
# 或者把某个不重要的进程得分调高,优先让它被杀
echo 500 > /proc/$(pidof some-worker)/oom_score_adj调整范围是 -1000 到 1000。设置为 -1000 相当于获得了“免死金牌”,内核不会主动终结该进程(当然,如果它自己内存泄漏导致 OOM,那也无力回天)。
对于使用 systemd 管理的服务,可以直接将配置写入服务单元文件,更为稳定可靠:
# /etc/systemd/system/mysql.service
[Service]
OOMScoreAdjust=-1000这比手动修改/proc目录更稳定,服务重启后配置依然生效。
更彻底的做法是为不同服务分配独立的内存配额,从根源上防止某个服务耗尽整台机器的内存:
# 创建一个 cgroup,限制 Ja va 服务最多用 8GB
cgcreate -g memory:/ja va-service
echo $((8 * 1024 * 1024 * 1024)) > /sys/fs/cgroup/memory/ja va-service/memory.limit_in_bytes
# 把进程加入这个 cgroup
echo > /sys/fs/cgroup/memory/ja va-service/cgroup.procs 这样一来,即使 Ja va 服务发生内存泄漏,其影响也被限制在自己的“笼子”里,不会波及到 MySQL 等其他关键服务。
Redis 默认不限制内存使用上限(未配置maxmemory)。一旦数据量激增,内存占用会直线上升,导致其 oom_score 迅速攀升,成为 OOM Killer 的首选目标。
# Redis 配置里一定要加这一行
maxmemory 6gb
maxmemory-policy allkeys-lru # 内存满了之后使用 LRU 算法淘汰旧数据某个存在内存泄漏的 C++ 服务,每小时内存增长 100MB。运行数天后,服务器内存被耗尽,OOM Killer 出手清理,可能误杀了旁边的 Nginx 或 MySQL。而那个泄漏的源头进程,却可能因为被监控系统重启而“逃过一劫”。
预防手段:使用 cgroup 为每个服务设置内存上限。让存在泄漏的进程在自己的配额内“自我了断”,避免殃及池鱼。
Docker 容器明明只分配了 2GB 内存限制,但 JVM 并未感知到此限制,默认按照物理内存的 1/4 来设置堆大小。结果堆内存超出容器限制,被容器自身的 OOM 机制杀死。
# JVM 启动时显式指定堆大小,不要依赖自动检测
ja va -Xms512m -Xmx1536m -jar app.jar
# 或者使用 JVM 的容器感知模式(JDK 10+)
ja va -XX:+UseContainerSupport -XX:MaxRAMPercentage=75.0 -jar app.jar很多人认为开启 swap 就能高枕无忧,OOM 永远不会发生。这其实是个误解。swap 只是将 OOM 发生的时间点向后推迟了,并非根治之法。
# 查看 swap 使用情况
free -h
# 如果 swap 也快满了,OOM 依然会到来
# 调整 swappiness:值越低,内核越倾向于使用物理内存,越不愿意用 swap
cat /proc/sys/vm/swappiness # 默认 60
echo 10 > /proc/sys/vm/swappiness # 数据库服务器常见配置过度依赖 swap 会导致大量的磁盘 I/O,使服务响应变得极其缓慢。因此,对于数据库这类对延迟敏感的服务,通常会将 swappiness 调至很低,宁可让内存紧张时早点触发 OOM 清理进程,也避免系统因大量 swap I/O 而陷入“卡死”的假死状态。
(1) Q:OOM Killer 是怎么选择杀哪个进程的?
A:通过计算每个进程的 oom_score 进行选择,分数最高的进程会被选中。oom_score 主要基于进程实际使用的物理内存占总内存的比例。管理员可以通过调整oom_score_adj(范围 -1000 到 1000)进行干预,-1000 表示该进程永不被 OOM 杀死。
(2) Q:如何防止关键进程被 OOM 杀死?
A:主要有三种方式:一是设置该进程的oom_score_adj = -1000;二是在 systemd 服务单元中配置OOMScoreAdjust=-1000;三是使用 cgroup 对服务进行内存隔离,让有问题的进程在自己的配额内崩溃,不牵连其他服务。
(3) Q:Linux 的内存 overcommit 是什么?有什么风险?
A:这是内核允许进程申请超过实际物理内存的虚拟内存的机制。malloc成功只代表获得了虚拟地址空间,真正的物理内存分配发生在首次访问时。好处是提高了内存利用率,风险在于极端情况下所有进程同时大量使用内存,导致物理内存和 swap 全部耗尽,触发 OOM Killer,可能杀死意料之外的关键服务。
(4) Q:OOM 发生后怎么排查是哪个进程导致的?
A:第一步,执行dmesg | grep -i oom查看内核日志,其中记录了被杀死进程的详细信息。第二步,结合系统监控(如 Prometheus、Zabbix),查看 OOM 发生前一段时间的内存使用趋势,找出哪个进程的内存占用持续增长,通常它就是根本原因。
(5) Q:swap 能避免 OOM 吗?
A:不能完全避免,只能推迟。当物理内存不足时,内核会将不活跃的内存页换出到 swap,以释放物理内存。但 swap 空间本身有限,且大量 swap 读写会引发严重的 I/O 性能问题,导致服务响应延迟暴增。因此,数据库等对性能敏感的服务通常会将vm.swappiness调至很低(甚至为 0),优先保证响应速度。
OOM Killer 这套机制,本质上是内核在“船即将沉没,必须抛弃部分货物”时做出的权衡。它试图扔掉那些“最不重要”的货物,但关于“重要性”的定义,是由内核自己的算法决定的,未必符合你的实际业务优先级。
一旦理解了 oom_score 的打分逻辑,你就能从被动应对转为主动干预:为关键服务戴上“护身符”,为次要任务贴上“优先清理”标签,并用 cgroup 构筑隔离区。最终目的,是让 OOM 发生时,损失能被控制在可预期、可管理的范围内。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。