引言 在聊今天的技术主角之前,先说个题外话。备受关注的《2025年博客之星年度评选获奖
在聊今天的技术主角之前,先说个题外话。备受关注的《2025年博客之星年度评选获奖名单》近期揭晓了,我们“小马过河R博客”团队很荣幸跻身年度百强之列。这无疑是个令人鼓舞的开始。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
好,言归正传。如果你近期关注AI领域,想必对一个名字不会陌生——OpenClaw。这个开源项目近期可谓风头正劲,刷爆了技术社区的各个角落。那么,它究竟是什么?又该如何上手运行?今天,我们就来深入拆解一番。

用一句话概括:OpenClaw 是一个能在你本地部署的AI智能体(Agent)框架。它的核心能力在于,你可以通过自然语言发出指令,它能自动执行一系列任务,比如整理文件、处理邮件、生成报告、运行脚本,甚至操控浏览器完成表单填写等操作。
这个项目曾用过Clawdbot、Moltbot等名字,由程序员彼得·斯坦伯格(Peter Steinberger)主导开发。其slogan“The AI that actually does things”(真正能做事的AI)相当直白地点明了它的抱负。

那么,它和我们熟知的ChatGPT有何本质区别呢?如果说ChatGPT是一个在你问询时提供建议的“聊天顾问”,那么OpenClaw就更像是你的“数字特工”。具体差异体现在几个层面:
它直接运行在你自己的电脑或服务器上,数据无需上传云端,隐私可控性高得多;拥有系统级别的权限,可以读写本地文件、执行命令、调用各类API;支持长期记忆,能够学习你的习惯,越用越“懂你”,无需反复交代背景;更重要的是,它能24小时在后台持续运行,如同一个不知疲倦的“数字分身”,随时待命。
有个更通俗的类比:你可以把OpenClaw看作是Menus这类自动化服务的“个人本地版”。Menus建立在一个统一的云端平台上,而OpenClaw则完全部署并掌控在你自己的机器里。
归根结底,OpenClaw 属于 Agent(智能体)范畴。它与传统“你问我答”式AI应用的核心区别在于主动性——它不仅能响应,更能主动推送消息、主动帮你完成工作。
传统的人工智能助手,比如大多数聊天机器人,基本停留在“动嘴”阶段:你说一句,它回一句。OpenClaw的突破性在于,它能自主完成“理解任务、拆解步骤、调用工具、执行操作、反馈结果”这一整套流程,实现了真正意义上的端到端自动化。
这套复杂的运行机制,主要由以下几个关键模块协同完成:
OpenClaw部署在用户的个人电脑或云服务器上,一旦启动便会持续运行,就像一个“永远在线”的虚拟员工。所有数据处理全程保留在本地,避免了上传第三方服务器带来的隐私与安全风险。用户可以通过WhatsApp、Telegram等即时通讯工具远程下达指令,AI接收到后便会自主执行。
OpenClaw可以连接Claude、GPT、DeepSeek等多种主流大语言模型,用户能根据任务需求灵活切换“大脑”。系统会根据任务类型,智能选择最合适的模型进行推理。更厉害的是其“子智能体”(sub-agent)机制,一个主AI可以自主调度多个功能专精的子AI,以协同方式完成复杂任务。
这是OpenClaw的核心能力,也是它从“思考”走向“行动”的关键。主要通过以下几种方式实现:
浏览器自动化:可以控制无头浏览器(如Chromium)进行网页浏览、信息抓取、表单填写等操作。
API集成:能够连接邮件、日历、电商、支付等各类平台的接口,实现自动发送邮件、预订、购物等功能。
文件处理:可以读取PDF、网页链接等内容,并自动生成摘要、思维导图或Markdown文档。
命令行操作:拥有在系统终端执行脚本、管理本地任务的能力。
举个具体例子感受一下:你只需要发一条消息“帮我总结昨天的会议录音,并发给团队”。OpenClaw便会自动执行以下链式操作:下载录音文件 → 调用语音识别模型转为文字 → 利用大模型提炼会议重点 → 生成邮件草稿 → 最终发送给指定团队成员。
OpenClaw具备“长期记忆”能力,能够记住用户过去的偏好、常用流程和工作习惯,真正做到越用越顺手。例如,如果它知道你每周一早上需要查看行业简报,便会自动搜集相关信息并准时推送。所有这些记忆数据同样存储在本地,确保了高度的私密性。
OpenClaw是一个完全开源的项目,代码公开透明,开发者可以自由修改、扩展功能。活跃的社区已经开发出大量插件和连接器,支持与Swiggy、支付宝、钉钉等众多应用集成。正是这种强大的扩展性和自动化潜力,让它被称为“最接近通用人工智能(AGI)的消费级项目”。
如果将上述原理详细拆解,其实就是构成现代AI智能体的那些核心组件。为了方便理解,我们可以做一个生动的类比:
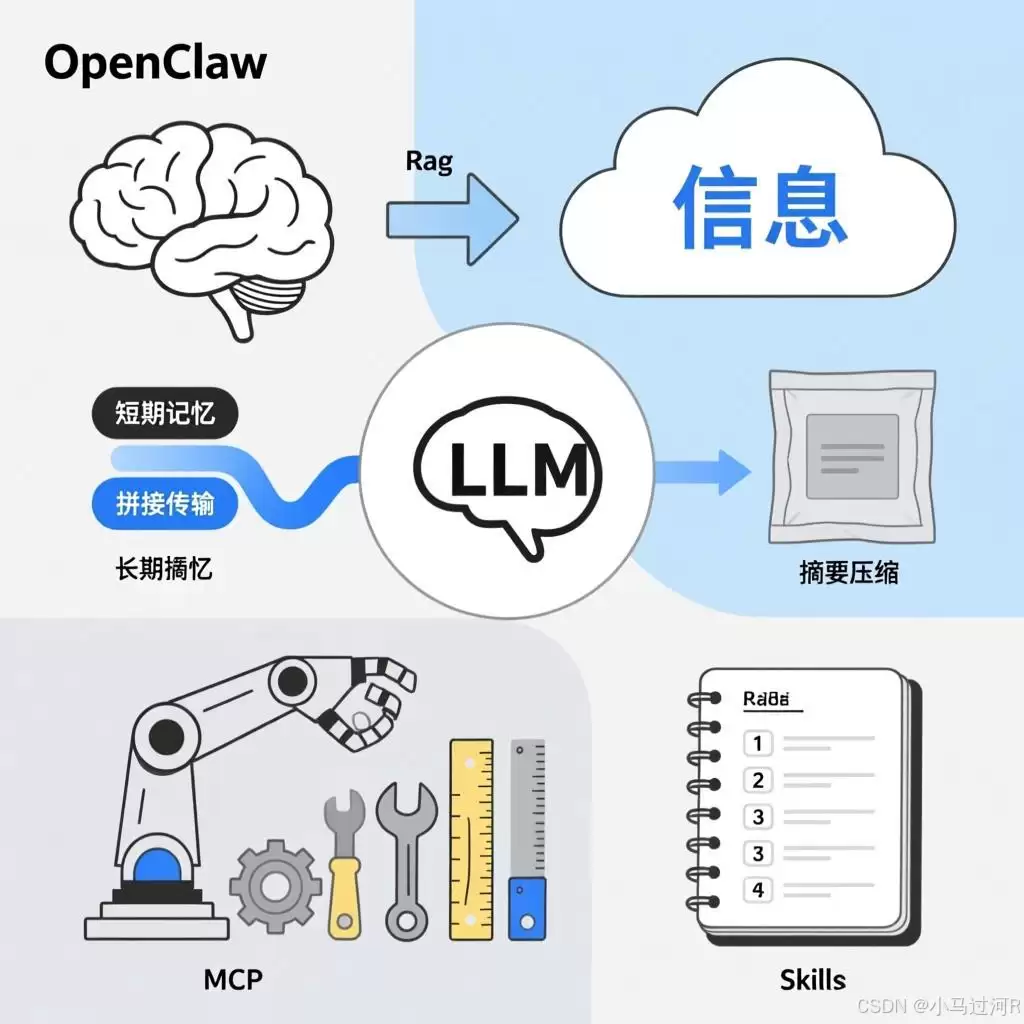
大语言模型(LLM)是智能体的“大脑”,负责思考与推理;RAG检索增强则是获取外部新知识的途径;记忆机制分为短期记忆和长期记忆,因为大模型本身不具备记忆功能,必须依赖外部系统——短期记忆主要是对话上下文的拼接传递,而长期记忆则会对海量历史数据进行摘要、压缩再传递;MCP协议相当于给大模型装上了能操作工具的“手”;各类MCP插件就是具体的“工具”;而Skills则像是针对特定场景的“经验手册”或“操作指南”,规定了一套处理问题的标准流程。
必须客观地说,OpenClaw目前仍处于快速迭代期,尚未达到高度成熟和“傻瓜化”的阶段,因此更适合有一定研发背景的技术爱好者尝鲜。但可以预见,其易用性的提升过程会非常迅速。
运行OpenClaw,首先需要准备一台闲置的云服务器或VPS(推荐使用香港或海外节点)。鉴于OpenClaw运行时权限较高,出于安全考虑,强烈不建议在主力工作机或存有重要资料的本地电脑上安装,最好在一激进分子立的、干净的服务器上进行部署。
项目的官方仓库地址是:https://github.com/openclaw/openclaw。其安装教程在README文档中已经介绍得比较清晰了。
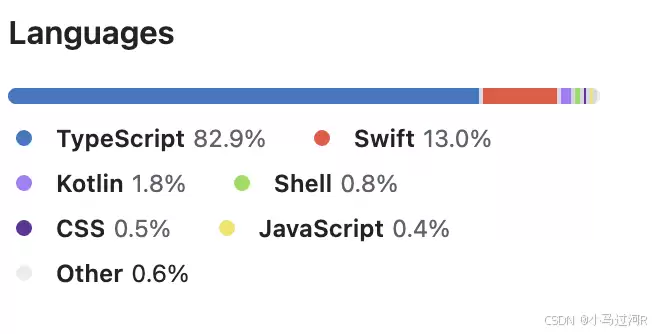
第一步,我们先了解下项目的技术栈。它主要基于TypeScript开发:
对于首次安装,最推荐的方法是使用其内置的向导:
npm install -g openclaw@latest
# 或者使用pnpm
# pnpm add -g openclaw@latest
openclaw onboard --install-daemon
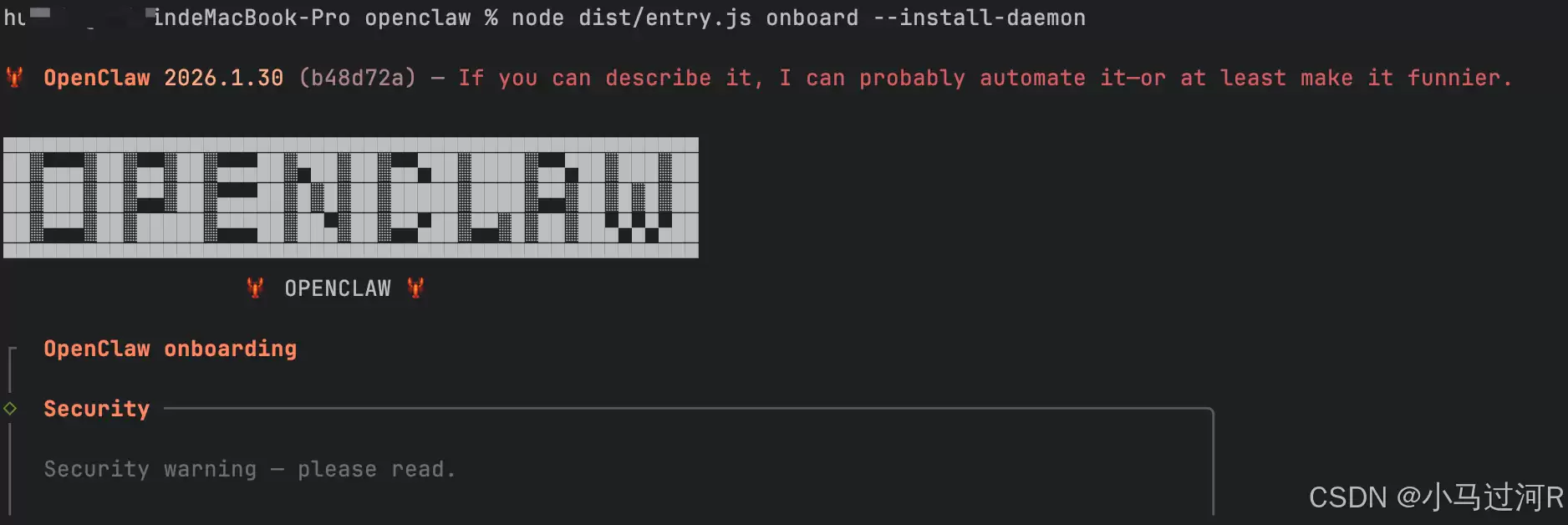
将pnpm openclaw onboard --install-daemon作为起点是个好选择,这个命令会自动安装守护进程,并引导你完成所有必要的配置步骤,只需跟着向导一步步操作即可。如果遇到报错,可以尝试运行node dist/entry.js onboard --install-daemon。
从官方文档可知,这个命令主要完成两件事:运行安装向导,配置网关、工作空间、通道和技能;安装Gateway守护进程(会注册为launchd或systemd用户服务),确保OpenClaw能保持运行状态。
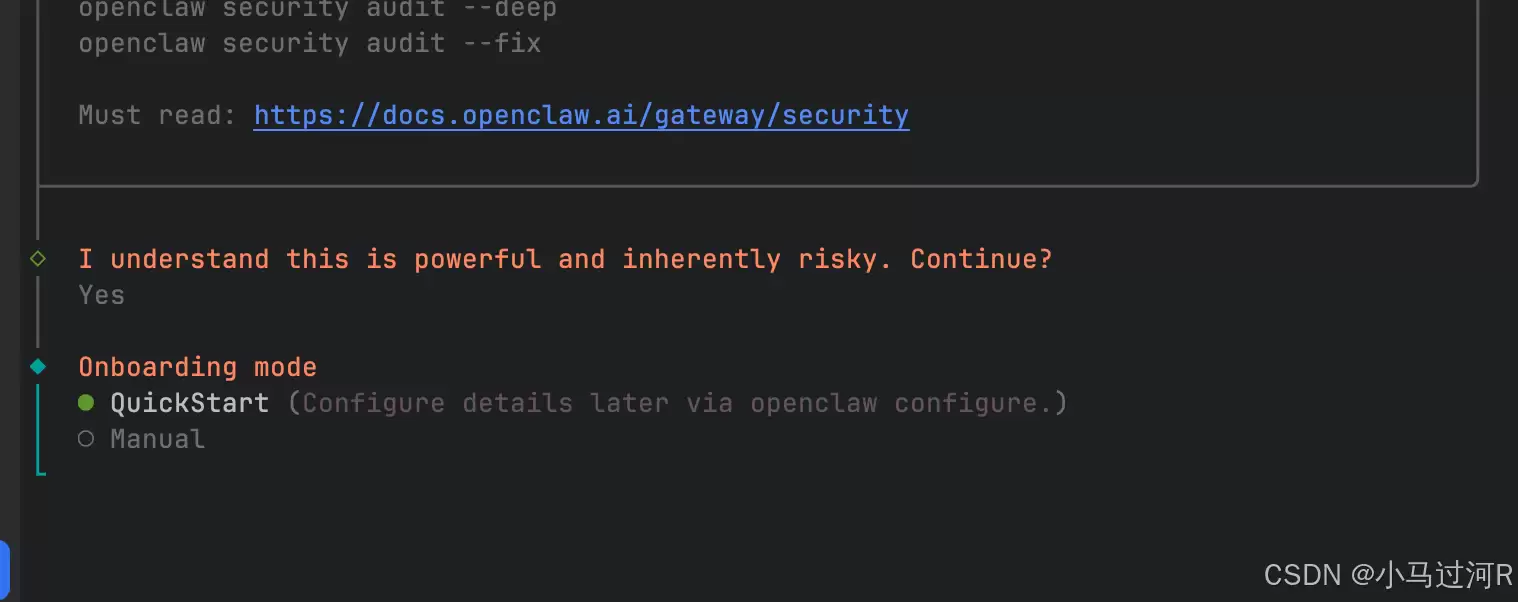
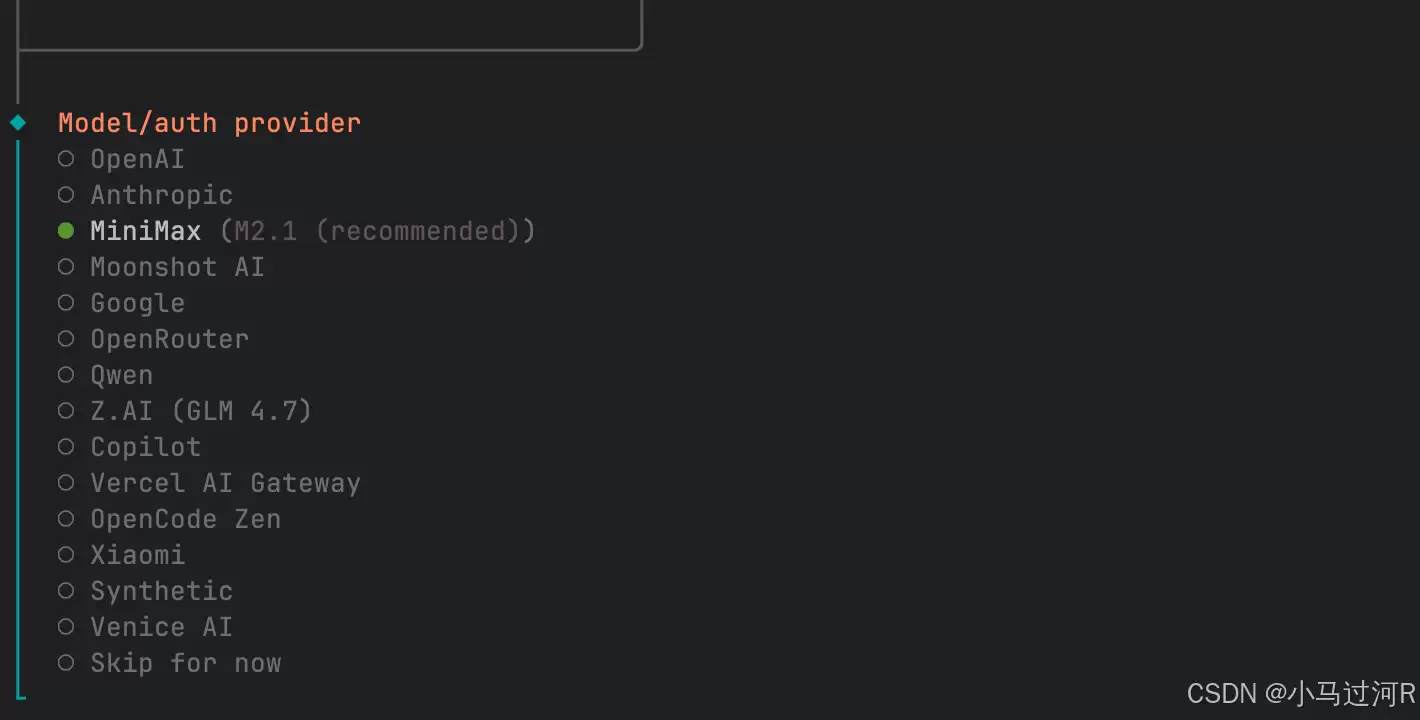
接下来是关键一步:配置AI模型。OpenClaw需要接入大语言模型的API才能工作,它支持GPT、Claude、GLM、Moonshot、阿里云百炼等多种模型。
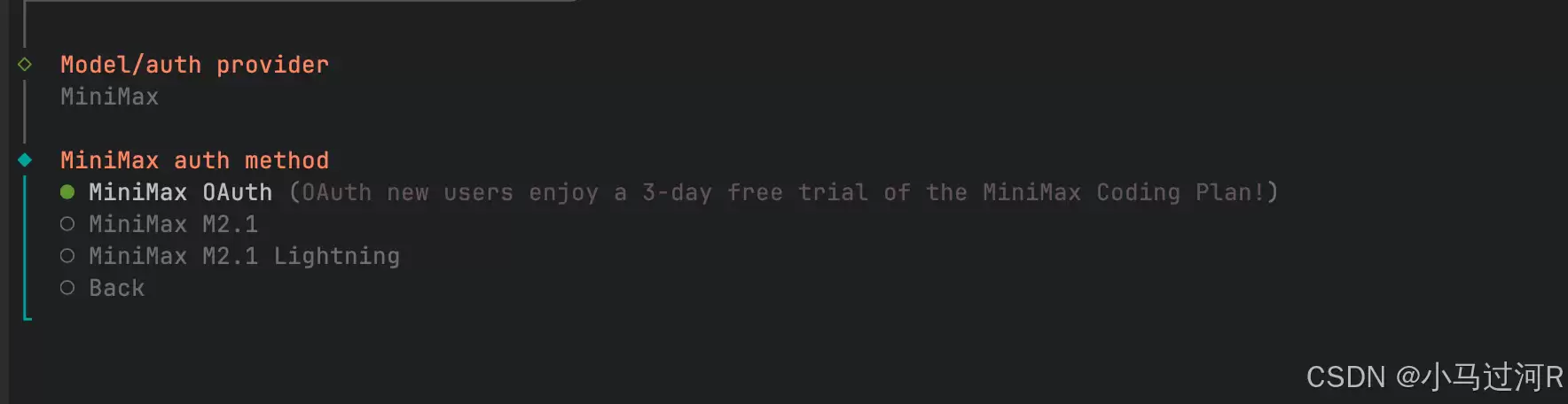
你需要前往对应的平台(如阿里云百炼、Moonshot、DeepSeek官网)创建并获取API Key。然后在OpenClaw中进行配置:可以通过命令行openclaw config set api_key your_api_key直接设置,或者通过上文提到的TUI界面(openclaw onboard)进行可视化配置。
至于模型提供方的选择,如果只是用于实验和体验,社区中有不少网友推荐使用千问等提供免费额度的模型,性价比很高(当然,具体效果还需自行尝试)。
对于习惯使用容器技术的开发者,Docker是更便捷的选择:
# 使用Docker Compose
docker-compose up
# 或者使用项目提供的脚本
bash docker-setup.sh


整体来看,运行流程并不算复杂。成功启动后,你大概能看到类似下图的界面。下图展示的是在IDE中借助Copilot辅助安装后的输出示例:

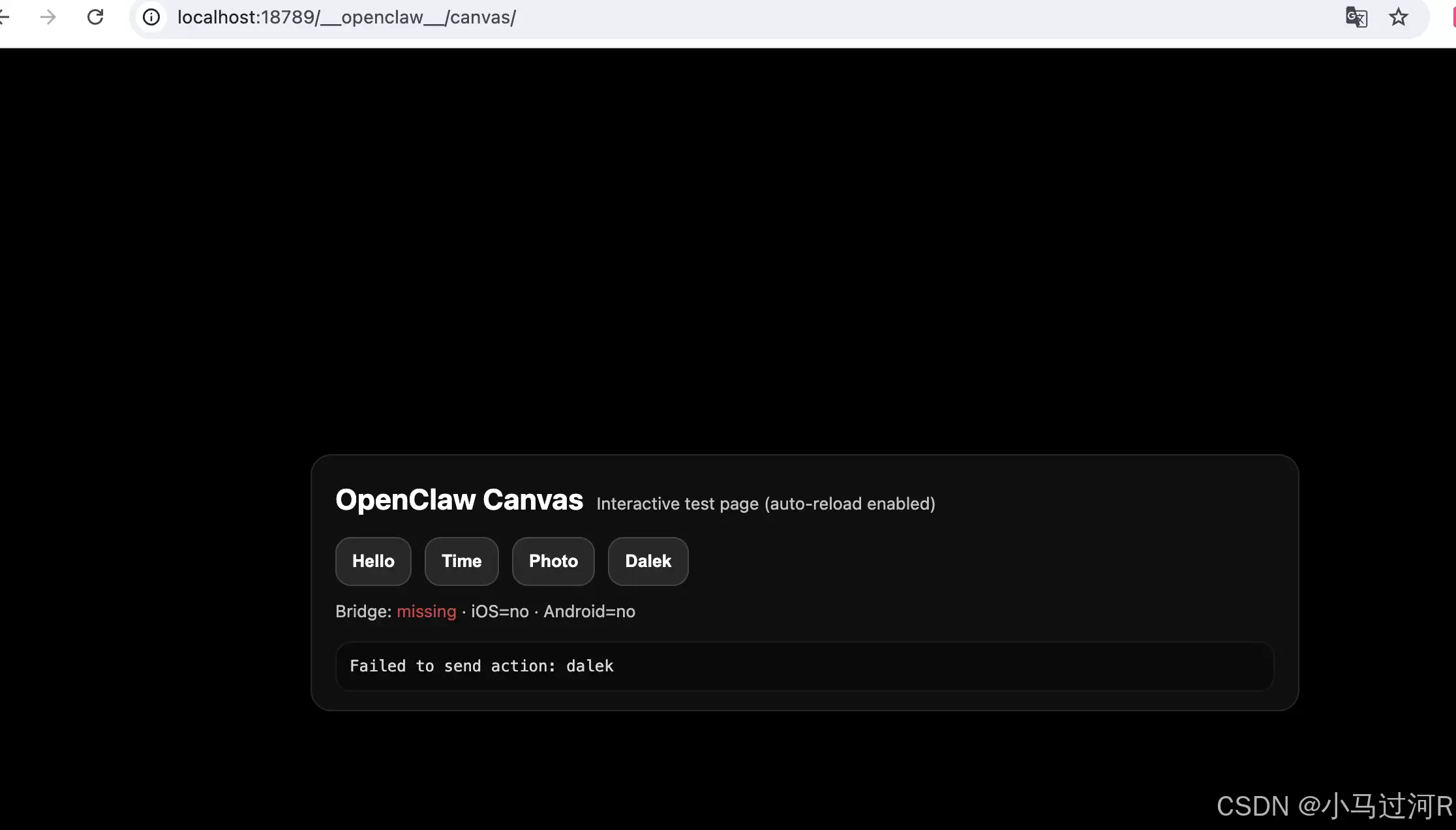
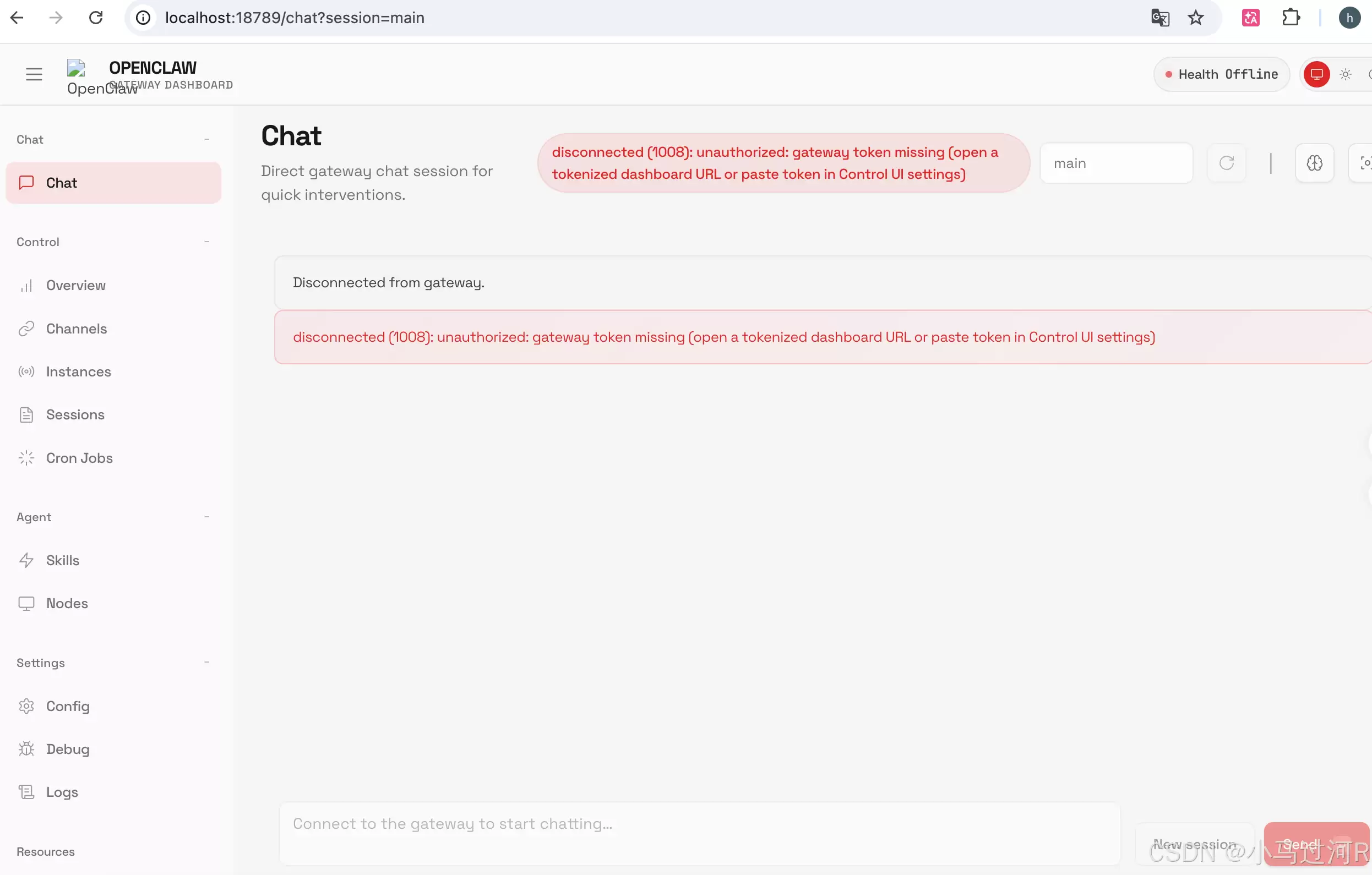
注意,图中间出现的标红错误提示,通常是因为网关令牌缺失导致的,在初始配置阶段可以暂时忽略。
当然了,如果本文的步骤概述仍不能满足你的详细需求,这里强烈推荐参考另一篇非常详尽的教程《OpenClaw(原 Clawdbot)钉钉对接保姆级教程 手把手教你打造自己的 AI 助手》,那篇文章可谓图文并茂,手把手教学,值得一看。
关于OpenClaw的初步介绍和运行指南就到这里。这个能真正“动手做事”的AI智能体,其潜力和应用场景非常值得深入探索。后续我们将继续分享它在实际场景中的具体运用案例,敬请期待。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。