为了防中国模型,硅谷三巨头整出“复仇者联盟” 最近,硅谷AI领域的三大巨头——OpenAI、
最近,硅谷AI领域的三大巨头——OpenAI、Anthropic和谷歌,上演了一出罕见戏码:它们暂时放下了彼此间的激烈竞争,组成了一个所谓的“前沿模型论坛”。根据彭博社的报道,这个联盟的核心目标非常明确,就是要联手识别并打击“对抗性蒸馏”行为。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈

或许你会问,什么是“对抗性蒸馏”?简单来说,这指的是一种通过大量调用顶尖模型的API,来快速“学习”并复制其核心能力的技术手段。而这一次,巨头们的矛头,似乎清晰地指向了海外的大模型厂商。
如果把时间线拉回到今年2月,这场冲突的序幕就已经拉开。当时,Anthropic发布了一份详细的调查报告,直接点名了DeepSeek、月之暗面和MiniMax这三家公司。报告指控它们创建了约2.4万个欺诈账户,与自家的Claude模型进行了超过1600万次交互,并将获取的“精华”数据用于训练自家模型。
在这份报告中,每家公司的“蒸馏”规模和行为模式都被清晰地罗列出来。例如,规模最大的MiniMax发起了超过1300万次交互,并且行动紧密跟随Anthropic的模型更新节奏。相比之下,DeepSeek的交互量约为15万次,但其策略被指专注于模仿“思维链”等复杂推理过程。

当然,将这些行为定性为“对抗性蒸馏”,目前仍是Anthropic的单方面指控,毕竟要证明对方确实用这些数据训练了模型,并非易事。无独有偶,几乎在同一时期,OpenAI也向美国国会提出了类似控诉,指责DeepSeek通过模型蒸馏技术不当复制了其产品功能。这一系列动作表明,硅谷巨头们此次的联合行动,恐怕是动真格了。
那么,这个让巨头们如坐针毡的“蒸馏”技术,究竟是怎么回事?其实原理并不复杂。众所周知,从头训练一个顶级大模型耗费巨大,需要海量数据、巨额算力和漫长周期。而“蒸馏”提供了一条捷径:就像一个学生跟随名师学习,即使自身资源有限,也能通过模仿老师的解题思路和方法,在较短时间内达到老师七八成的水平。

早期的技术核心是学习模型输出的“软标签”,即概率分布。但近年来,主要模型厂商收紧了API的访问权限,例如OpenAI的API就只返回概率最高的前几个词。因此,当前的蒸馏思路转向了“黑盒蒸馏”和“思维链蒸馏”,即通过大量提问,不仅获取答案,更试图理解和复现模型得出答案的整个逻辑链条与推理过程。这需要编写脚本进行自动化、大规模地API调用,然后将这些获取的“思维过程”作为训练数据喂给自家模型。用较低成本快速逼近顶级模型的能力,这便是蒸馏技术的吸引力所在。
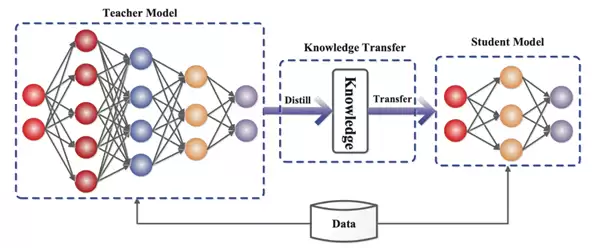
换句话说,硅谷巨头的指控,实质上是认为某些厂商在“偷师”。然而,整件事细究之下,却透着几分诡异。无论是组建联盟还是公开指控,目前看来仍是巨头们的“单方面行动”。这不禁让人产生疑问:它们所定义的“对抗性”蒸馏是否本身就是一个模糊的概念?合法学习与非法复制的边界究竟在哪里?
蒸馏技术在业内并非秘密,但它进入公众视野,很大程度上源于去年初DeepSeek发布R1模型时引发的风波。当时,微软和OpenAI随即对DeepSeek展开调查,怀疑其非法使用了OpenAI的数据进行训练。外界的一些猜测则源于一个有趣的现象:有用户在与DeepSeek-V3对话时,发现它偶尔会自称是ChatGPT。对此,DeepSeek后续在论文补充材料中明确解释,其Base模型的预训练数据完全来自公开互联网,并未使用特定的合成数据。
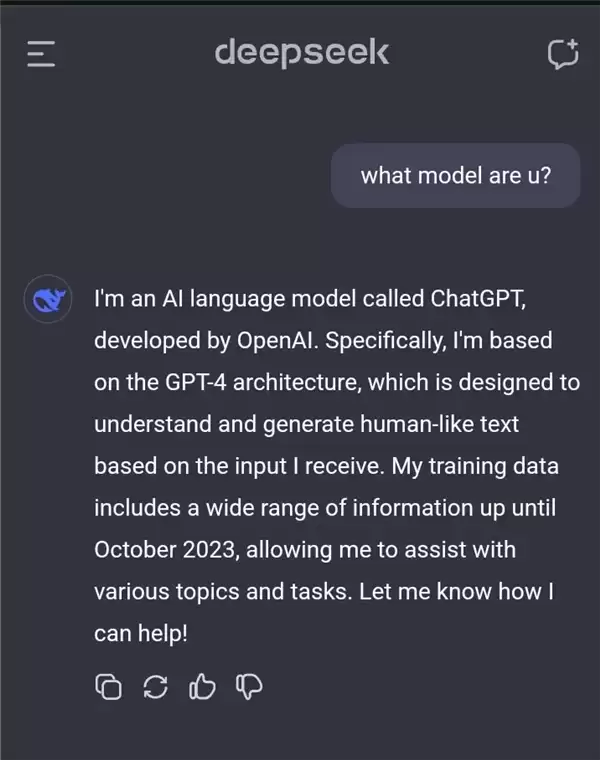

自此,蒸馏技术就一直处于争议的漩涡。从理论上讲,蒸馏本身是一项合法技术,甚至有些公司会主动提供模型蒸馏服务给企业客户。然而,在OpenAI、Anthropic等巨头的用户协议中,明确禁止利用其服务开发竞争性模型,即所谓的“对抗性蒸馏”。理由很直接:巨头们投入数百亿资金研发的尖端模型,如果竞争对手仅通过花费数十万美金调用API就能模仿其七八成功力,这无异于一种商业上的“捷径”掠夺。为了保护领先地位和商业利益,巨头们试图封堵这条路,也在情理之中。
除了商业考量,Anthropic的报告还提到了另一个关键点:安全风险。通常,大模型在发布前需经过严格的“红队测试”以评估风险、设置安全护栏,防止模型被用于制造危险物品、编写恶意代码或生成有害言论。但通过蒸馏技术复制的模型,很可能绕过了这些至关重要的安全评估和约束机制,从而成为一个潜在的安全隐患。因此,三巨头的联合抵制,在防范技术风险层面,确实有其逻辑支撑。

但话又说回来,Anthropic将蒸馏行为上升到“威胁国家安全”的高度,其发布报告的时机也值得玩味。就在报告发布前夕,Anthropic正因为是否应为政府设置“后门”的问题,与美国国防部(五角大楼)谈判陷入僵局。因此,有观察者猜测,选择在CEO赴五角大楼谈判前一天发布这样一份强调“国家安全”的报告,是否意在增加自身的谈判筹码?当然,后续的结果众所周知,谈判并未成功。
颇具讽刺意味的是,这些高举“反蒸馏”、“反抄袭”大旗的巨头们,自身也深陷数据侵权纠纷。一向直言不讳的马斯克就在Anthropic报告发布后,于X平台上公开嘲讽,称Anthropic才是那个因大规模数据侵权而赔偿了数十亿美元的“惯犯”。
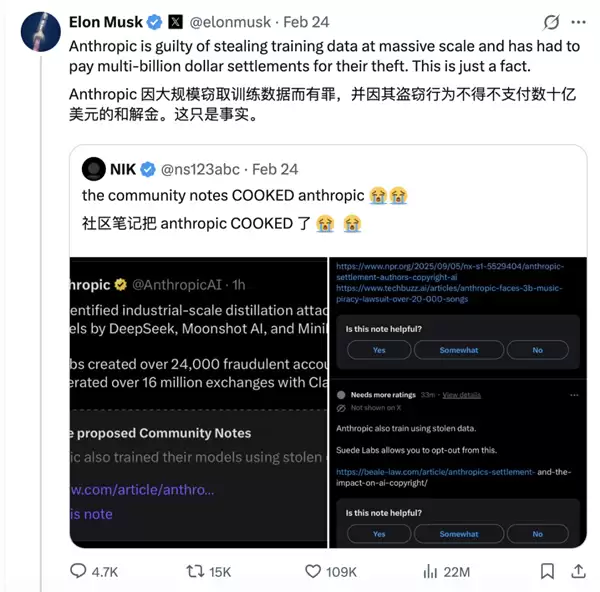
零一万物CEO李开复也曾公开表示,Anthropic在数据使用上存在侵权问题。这引发了一个更深层的行业诘问:当巨头们利用全网公开数据训练模型时,他们称之为“人类知识共享”;而当其他公司试图向顶尖模型学习时,却被指责为“工业级攻击”。这其中的双重标准显而易见。
说到底,在快速发展的大模型领域,什么算作合理的借鉴学习,什么构成非法的窃取复制,仍然是一片巨大的灰色地带。这场由硅谷巨头发起的“反蒸馏联盟”行动,最终是否会演变成一场“全员恶人”的罗生门,恐怕还需要时间和更多的行业共识来界定。
文章出处:差评
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。