










Stable Diffusion新手快速入门教程,零基础小白如何学习Stable Diffusion绘画的经验

摘要
Stable Diffusion新手快速入门:零基础如何跑通第一张图 不少朋友对Stable Diffusion AI绘图兴趣浓
Stable Diffusion新手快速入门:零基础如何跑通第一张图
不少朋友对Stable Diffusion AI绘图兴趣浓厚,但面对它繁多的功能和略显复杂的界面,难免心生怯意,迟迟不敢迈出第一步。
今天分享的,正是一条为零基础新手设计的Stable Diffusion学习路径。与其一开始就钻研高深技巧,不如先掌握这套快速上手的心法,或许更能帮你打开局面。
实话实说,对比即梦、可灵、Midjourney这类工具,Stable Diffusion的功能确实更庞大,操作界面也更专业,这意味着需要学习的内容更多,初始门槛也相对较高。
那么,新手该怎么破局?关键在于别贪多。起步阶段,根本不需要急着去啃透所有高级功能。最先要弄明白的,其实是三个最朴素的问题:Stable Diffusion到底是什么?它能干什么?以及,如何用它快速生成第一张图,亲自感受一下?至于ControlNet、模型训练这些进阶玩法,完全可以往后放。
一旦把上面这几个基础问题搞清楚了,哪怕在SD的浩瀚知识海洋里这只是沧海一粟,你也已经完成了从0到1的跨越。有了这个地基,后续无论想从1学到10,还是从10进阶到100,道路都会顺畅很多。
所以,这里想强调一个学习理念:接触任何新事物,优先寻找那条最简短的路径,迅速掌握其核心基础。不必追求起步就完美,更不必妄想一口吃成胖子。过陡的学习曲线,反而容易让人半途而废。遵循由简入繁、由易到难的原则,掌握新技能的过程会顺利得多。
下面这篇文章的结构,就完全遵循了这个“最小闭环”的学习过程。一起来看看,如何快速产出你的第一张SD作品。
一、什么是Stable Diffusion?
Stable Diffusion,中文常译作“稳定扩散”,大家习惯简称它为SD。
它是一个开源的AI绘画模型,由CompVis团队与Stability AI联合开发。其核心能力,就是根据用户输入的文字描述,生成相应的高质量图片。
简单来说,SD和Midjourney、可灵、即梦属于同类,都能“文生图”或“图生图”。但SD的绘图功能更细分,可控性也更强,因此可供深入挖掘的知识点自然就更多了。
二、什么是Stable Diffusion WebUI?
SD本身是靠代码运行的,直接使用需要输入各种指令,这对非专业人士极不友好。于是,GitHub上一位名叫automatic1111的开发者,将所有这些功能整合起来,并提供了一个可视化操作界面。我们通常所说的SD操作界面,指的就是这个WebUI。用户只需通过浏览器访问这个UI界面,就能轻松使用SD进行绘图,无需与代码打交道。
不用担心抽象,后续章节会直接展示WebUI长什么样。
三、Stable Diffusion能干什么?
顾名思义,SD的核心就是“绘图”。它所有的功能都围绕这两个字展开。例如:文生图、图生图、局部重绘、高清修复、通过插件控制画面细节、训练专属模型(即“炼丹”)等等。
四、怎样能使用Stable Diffusion绘图?
目前主要有两种方式:本地运行和云端部署。
1、本地运行:
需要在本地电脑下载安装包进行部署。这种方式对电脑配置,尤其是显卡要求很高。如果你的初衷只是体验一下,或者用于自媒体内容创作,并非专业美术工作者,那么完全可以使用云端方案,没必要为了用SD而专门购置高配电脑。
优点:一旦部署完成,后续可免费使用。
缺点:对电脑硬件配置要求极高,部署过程可能涉及技术门槛。
2、云端部署:
这里推荐几个可直接在网页端使用SD的平台:
- 哩布哩布AI(LiblibAI),网址:https://www.liblib.art/
- 端脑云(Cephalon Cloud),网址:https://cephalon.cloud/#/aigc
- C站(civitai),网址:https://civitai.com/
优点:对电脑配置几乎无要求,有浏览器就能用,开箱即用。
缺点:通常需要付费,但费用一般不高,且常有免费额度可供体验。
五、实战:使用webUI出第一张图
把前面的基础概念理清之后,终于可以动手实操了。
接下来,我们就以“哩布哩布AI”网站为例,跑通生成第一张图的完整流程。选择它,主要是因为平台每天会提供免费算力,非常适合学习和体验,能最大限度降低初期成本。
操作步骤:
1、登录liblibAI:https://www.liblib.art/
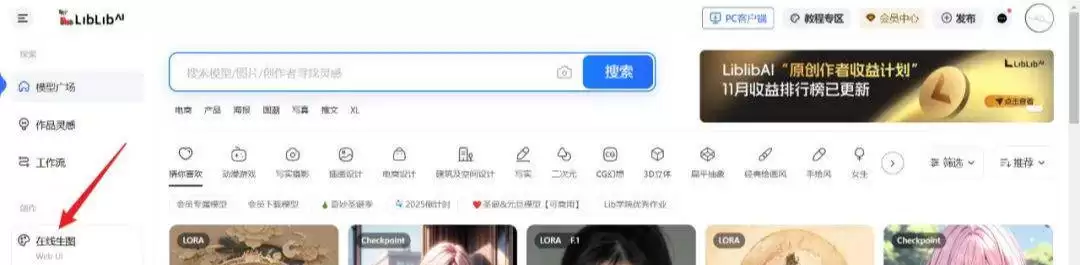
2、点击“在线生图”
3、选择参数和填入提示词。如果不知从何下手,可以直接参考下图所示的参数进行设置。

这里解释几个关键选项:
CHECKPOINT:即SD的大模型,也叫底膜。这是出图必须选择的,它决定了图片的整体风格。想生成写实风图片就选写实类大模型,想生成二次元图片就选二次元类大模型。
VAE:全称变分自编码器(Variational Autoencoder)。初期了解即可,通常保持默认设置,不需要改动。
提示词:这里用文字描述你想要生成的画面,要什么就写什么。建议将中文描述翻译成英文,效果通常更好。你可以直接复制下面的提示词体验:
Chinese wedding photos,(Masterpiece, best quality, Beautiful :1.2),(High Detail skin :1.2),high resolution, extreme detail,1 girl,Asian,bun,hairpins,beautiful face,delicate eyes,light makeup, earrings,necklace,bracelet,(Exquisite wedding dress :1.5),sexy figure,elegant posture,black heels,lazy,Languor, movie lighting,warm light,ray tracing,depth of field,movie texture,medium long lens,soft light,
负向提示词:用于描述你不希望出现在画面中的元素,例如低质量、模糊、畸形的手部等。初期可直接使用默认的负面词库。
接下来进行参数设置:

4、出图
所有参数设置完毕,点击“生成”按钮,等待片刻,就能看到你的第一张SD作品了:

六、结语
恭喜!走到这一步,意味着你已经掌握了Stable Diffusion最基础的绘图流程,成功实现了从无到有的“最小闭环”。
正如开头所言,目前所掌握的,在SD的庞大体系里确实只是冰山一角。但万事开头难,这个从0到1的突破恰恰是最关键的。有了这个扎实的起点,后续无论是想深入钻研提示词工程,还是探索各类控制插件,路径都会清晰得多。一步步来,从1到10,再到100的突破,自然水到渠成。
来源:互联网
本网站新闻资讯均来自公开渠道,力求准确但不保证绝对无误,内容观点仅代表作者本人,与本站无关。若涉及侵权,请联系我们处理。本站保留对声明的修改权,最终解释权归本站所有。
