










AI编程能力哪家强?阿里通义千问 Qwen 推 CodeElo 基准,OpenAI o1-mini 夺冠超 90% 人类程序员

摘要
阿里通义千问推出CodeElo基准:让AI与人类程序员同台竞技 最近AI圈有个挺有意思的新动向:
阿里通义千问推出CodeElo基准:让AI与人类程序员同台竞技
最近AI圈有个挺有意思的新动向:阿里通义千问团队搞了个叫“CodeElo”的基准测试。简单说,它用上了竞技游戏里常见的Elo评级系统,目的不再是让模型们自己“卷”,而是直接把大模型的编程水平,拉到人类程序员的赛场上比一比。
项目背景
用大语言模型来写代码、补全代码,已经是AI落地最热门的场景之一了。但说实话,想准确评估一个模型真实的编程能力,一直是个老大难问题。
现有的不少评测基准,像LiveCodeBench、USACO这些,多多少少都有些局限。比如,缺乏足够健壮的私有测试用例,没有专门的评判系统适配,执行环境也时不时来个“变脸”。这些因素堆在一起,让评测结果有时看起来总隔着一层纱,不够透彻。
CodeElo:借力CodeForces,打造更精准的LLM评估体系
那怎么解决这些痛点呢?通义千问团队给出的答案就是CodeElo。这个基准的核心思路很巧妙——直接借助以严格著称的编程竞赛平台CodeForces的题目和评判系统。模型生成的代码,会像人类选手提交的代码一样,在CodeForces的真实环境中接受检验。这样一来,误报、环境不一致这些老问题就迎刃而解了,连那些需要特殊评判机制的题目也能搞定。更重要的是,Elo评级本身就是为了衡量人类选手相对水平而设计的,用它来给模型打分,模型和人类程序员之间的表现高低,一眼就能看明白。
CodeElo三大核心要素:全面、稳健、标准化

这套基准能站稳脚跟,靠的是下面这三个扎实的设计:
- 全面的问题选择:题目可不是随便抓的。它们来自CodeForces,并且按照比赛分区、难度级别和算法标签做了精细分类,确保评估能覆盖不同维度,足够全面。
- 稳健的评估方法:这才是关键所在。代码直接提交到CodeForces平台进行测试,利用其原生的、成熟的评判机制。这意味着不需要依赖可能泄露的隐藏用例,就能获得准确可靠的反馈,评估的稳健性大大提升。
- 标准化的评级计算:采用经典的Elo系统。它不只是看题目有没有做对,还会综合考虑问题的难度,并对提交错误进行扣分惩罚。这实际上是在激励模型产生更高质量、更可靠的解决方案,为评估编码模型提供了一个既细致又有效的量化工具。
测试结果
那么,实测效果如何呢?研究团队对30个开源大模型和3个专有模型进行了测试。结果有点惊人:OpenAI的o1-mini模型一骑绝尘,拿到了1578的Elo评分,这个成绩已经超过了平台上90%的人类参与者。在开源模型阵营里,QwQ-32B-Preview以1261分拔得头筹。
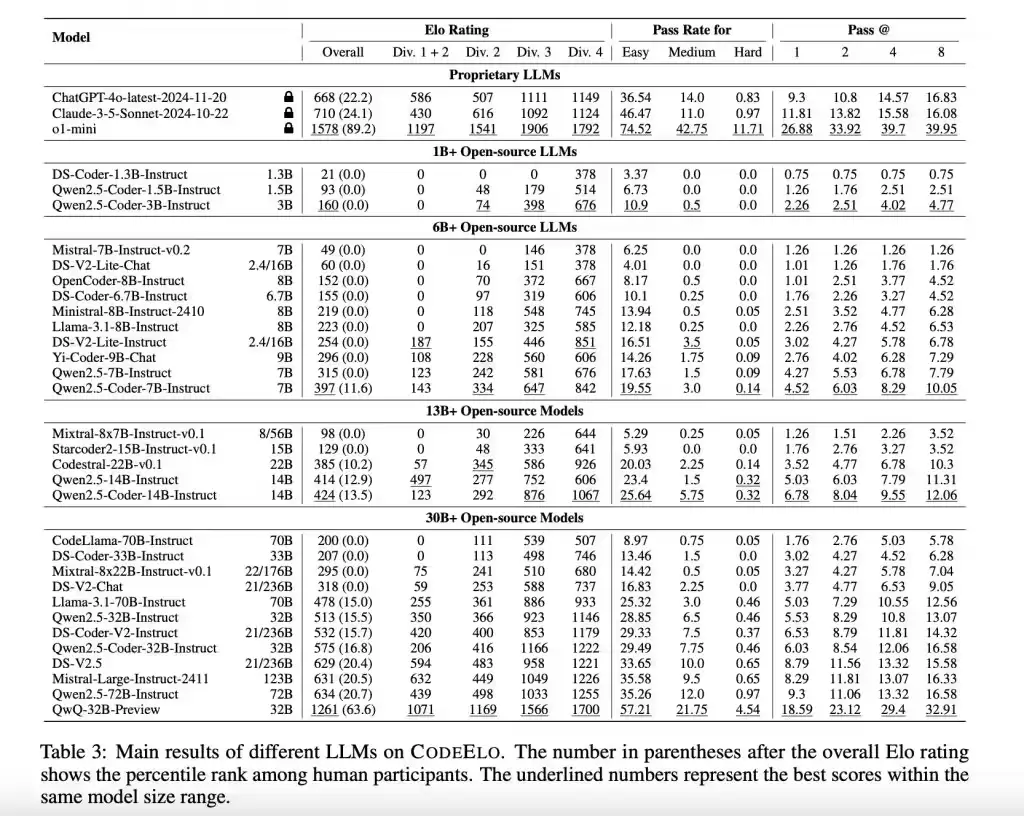
不过,亮眼成绩的另一面,也暴露出现阶段模型的短板。测试发现,很多模型在面对一些简单问题时依然显得吃力,其排名通常徘徊在人类参与者的后20%。进一步分析模型在不同算法类别上的表现,会发现它们在“数学”和“实现”类题目上比较出色,但在“动态规划”和“树形算法”这类更需要复杂逻辑推导的题目上,就显得力不从心了。
还有个有趣的发现:模型在使用C++语言编码时,整体表现更佳。这倒和全球竞技程序员们的普遍偏好不谋而合。这些结果清晰地勾勒出了当前大语言模型在编程能力上的优势区和薄弱点,也为后续的改进指明了具体方向。
来源:互联网
本网站新闻资讯均来自公开渠道,力求准确但不保证绝对无误,内容观点仅代表作者本人,与本站无关。若涉及侵权,请联系我们处理。本站保留对声明的修改权,最终解释权归本站所有。
