










谷歌分布式训练开启另一轮扩展定律!百万芯片高压高故障仍然零全局停机

摘要
谷歌最新名为Decoupled DiLoCo的研究,直接把这种锁步模式扔进了历史博物馆 如今训练最先进
谷歌最新名为Decoupled DiLoCo的研究,直接把这种锁步模式扔进了历史博物馆
如今训练最先进的大语言模型,存在一个听起来颇为荒谬的常态。
不妨想象一下:一支由上万名抄写员组成的团队,正在共同誊写一部巨著。所有人必须步调一致,每写一个字,就要互相核对一次,确保笔迹完全相同。只要其中一人打了个喷嚏,慢了半拍,整个誊写工作就得停下来等他。
而谷歌最新一项名为Decoupled DiLoCo的研究,正是将这种“锁步”模式彻底送进了历史博物馆。

它的核心思路是,让一个庞大集群里的不同部分可以“各干各的”,再通过一种极其聪明的方式进行异步汇合。最令人惊叹的成果在于,当模拟数百万芯片在频繁故障的高压环境下训练时,这套系统实现了零全局停机时间,而模型的最终性能却丝毫未打折扣。
解构锁步的困境
当前的大模型训练,普遍采用一种称为SPMD(单程序多数据流)的范式。你可以将其理解为一个极其庞大且严苛的方阵,所有计算芯片必须保持完全一致的步调。
这种对参数一致性的绝对执念,让整个系统变得异常脆弱。一块问题芯片、一次微小的网络抖动,都足以让这个价值数亿美元的庞大集群陷入停滞。
研究团队采用了一个非常有趣的视角,类比计算机科学中的CAP定理,来重新审视模型训练的瓶颈。他们认为,传统的SPMD训练堪称“一致性原教旨主义者”——为了确保每块芯片看到的模型参数都分毫不差,不惜牺牲系统的可用性和分区容错性。
然而,在成千上万块芯片需要协同工作数月的现实场景中,硬件故障几乎如同家常便饭。每一次故障都意味着停机、等待、恢复和巨大的算力浪费,这就像一个繁忙的国际机场,仅仅因为一盏信号灯故障,就不得不关闭所有跑道。
破局之道,正是Decoupled DiLoCo。

其思路简单而优雅:将铁板一块的大集群,拆分成若干个独立运作的小团队,每个团队被称为一个“学习者”。每个学习者都拥有完整的模型副本,可以在自己的数据分区上埋头训练,互不干扰。即便某个学习者遭遇硬件崩溃,其他学习者的工作也完全不受影响。
协调这些学习者的重任,则落在一个名为“同步器”的中央节点身上。但这位“调度员”从不要求所有人立正站好。它会按照预设的时间节奏,随机地向所有正在工作的学习者发出邀约,收集它们训练好的模型参数更新。关键在于,它只等待达到一个最低数量的学习者响应,就能完成一次全局参数的优化与合并。那些因为故障或网络延迟而“迟到”的学习者,会被暂时跳过,等待下一次同步机会。整个过程,训练从未停歇。
这种设计带来了实实在在的收益。一项模拟数据揭示了惊人的对比:假设单个芯片平均一年出一次故障,在一个由240万块芯片组成的庞大集群中,没有弹性功能的常规数据并行训练,系统有效工作时间仅为18%。即便加入了动态调整功能,有效工作时间也仅能提升至40%。
而当切换到Decoupled DiLoCo,并将集群拆分为16个独立学习者时,系统有效工作时间飙升至86%,系统无故障运行的时间占比更是保持了近乎完美的99%。

优雅的混沌工程实验
为了验证这套框架的真正鲁棒性,研究团队做了一件很酷的事情:他们在代码中模拟了一个“修罗场”,通过混沌工程的原则,人为地注入各种故障。他们设定了故障发生的频率、恢复时间,甚至芯片处理速度的随机波动,以此来考验系统的极限。
结果令人振奋。

在一个包含8个学习者、模拟120万块芯片、故障环境极其恶劣的实验中,Decoupled DiLoCo的系统有效工作时间保持在88%,而同样条件下的传统训练模式仅有58%。
更关键的是,在应对这些混乱的同时,模型在文本和视觉任务上的最终表现,与那些在完美无故障环境下训练出的模型,依然保持了同等水平。在一个50亿参数的密集模型上,无论是平均文本得分还是视觉得分,其变化几乎可以忽略不计。
这意味着,训练团队不再需要面临“牺牲模型质量换取稳定性”或“牺牲稳定性换取质量”的艰难抉择。现在,他们可以同时拥有两者。
捡拾算力与异构硬件大一统
这种解耦架构还释放了两个令人兴奋的额外红利。
第一个是“算力撷取”。大规模训练集群的利用率很少能一直保持100%。例如,一些即将被抢占的云计算资源,或者分布在不同地理位置的闲置硬件,都可能出现临时可用的算力窗口。Decoupled DiLoCo可以像一个灵活的智能插线板,随时接入这些临时可用的算力,将其作为新的学习者加入训练。
论文展示了一个实验:当可用算力在训练过程中动态增加了300%时,模型训练不仅没有崩溃,总训练时间反而被压缩到了原来的62%,且最终性能与基线模型持平。

相比之下,传统数据并行模式由于沉重的状态传输和同步开销,在这种动态扩缩容的场景下,所能获得的时间收益要小得多。
第二个红利是“异构计算大一统”。不同代际、不同型号的芯片可以无缝地加入同一个训练任务。在一次实验中,研究者混合使用了两种不同型号的TPU,即使它们之间的处理速度存在接近20%的天然差异,通过Decoupled DiLoCo和一个聪明的自适应等待机制,系统依然能够高效运转,模型的最终效果与纯同步设置下的结果无异。
这为企业平滑过渡到新硬件,或者充分利用现有的旧硬件库存,打开了充满想象力的新空间。

上图清晰地展示了在不同同步策略下,运行速度不一的学习者们的忙碌状态。第一行是保守的“等待全部学习者到齐”模式,产生了大量空闲时间。第二行是激进的“不等待”模式,虽然忙碌,但同步过于零碎,效率不高。第三行则是论文采用的自适应策略,它在不造成无谓等待的前提下,尽可能地汇集了更多学习者的贡献,达成了效率与模型质量的绝佳平衡。
规模定律依然有效
一个始终悬在分布式训练方案头上的疑问是:这种松耦合的设计,会损害模型的最终能力吗?尤其是在模型规模和训练数据量都急剧增大的前沿探索中。
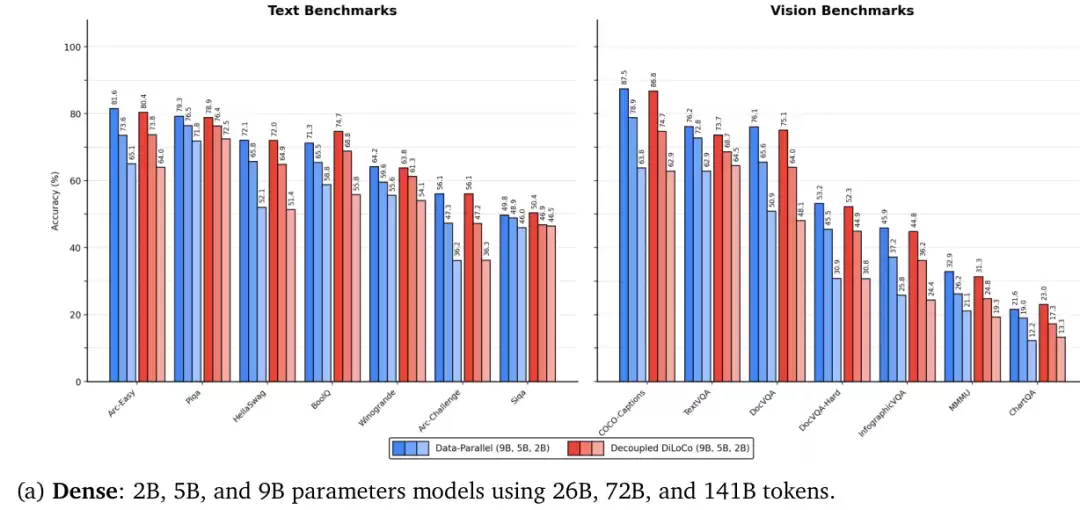
答案是否定的。论文系统地验证了从20亿到90亿参数的密集模型,以及28亿和38亿激活参数的混合专家模型。在所有模型尺度上,Decoupled DiLoCo都取得了与传统同步数据并行训练相匹配的下游任务性能。无论是对文本理解的平均得分,还是对图表、文档等多模态内容的理解能力,其差异均处在可忽略的范围内。

这项研究直接挑战了“同步是必须的”这一默认前提。它用一个极简的、异步的、对故障极度友好的系统设计,证明了一个关键观点:在大规模AI训练中,我们可以通过牺牲一些无关紧要的、瞬时的一致性,来换取更为宝贵的系统可用性和硬件容错性。
当AI训练的规模持续向物理极限扩张,当硬件集群的异构性和地理分布性日益成为常态,这种从追求“全局绝对一致”转向拥抱“局部独立、异步协同”的设计理念,很可能将成为新一代AI基础设施设计的基石。
若将大规模AI训练比作一场马拉松,那么与其让一个万人方阵踢着正步、艰难且脆弱地走向终点,不如让每个小队跑出自己的节奏与效率,最终在终点前完成一次精彩而稳健的智慧汇合。
来源:互联网
本网站新闻资讯均来自公开渠道,力求准确但不保证绝对无误,内容观点仅代表作者本人,与本站无关。若涉及侵权,请联系我们处理。本站保留对声明的修改权,最终解释权归本站所有。
