










喂给AI的Skill正让它变笨!清华团队发现大模型经验复用的黄金法则

摘要
清华大学与EvoMap团队的最新研究,呈现了一个完全反常识的结论 在AI智能体开发领域,一个
清华大学与EvoMap团队的最新研究,呈现了一个完全反常识的结论
在AI智能体开发领域,一个普遍的直觉是:给模型的经验手册越详尽,它应对新任务的能力就越强。然而,清华大学与EvoMap团队的最新研究,却给出了一个完全反常识的结论。你猜怎么着?给模型提供长达两千五百个Token的详细纠错“技能包”,反而会导致基准测试通过率大幅下跌;而换成仅两百多个Token的精简控制指令,性能却能实现逆势飙升。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
让智能体吸纳过往经验来提升任务表现,无疑是当下最热门的前沿方向之一。人们习惯性地认为,经验越丰富、上下文越完整,模型就越能举一反三。但这项研究的结果,直接挑战了这一根深蒂固的认知。

业界长期以来的做法,是将机器的犯错经历打包成详尽的说明文档,希望模型能像人类一样阅读理解。但研究团队打破了这一惯性思维,提出了一个革命性的转变:将长篇大论的程序化“技能”,转化为短小精悍的“策略基因”。

通过多达4590次的严格对照实验,结论清晰而有力:面向机器推理的控制型经验载体,其效率远高于面向人类阅读的文档型载体。这为智能体的“测试时演化”指明了一条全新的路径。
经验重载的迷思
当前,大语言模型智能体正朝着积累并复用经验的方向快速进化。从文本反思、外部记忆到可执行的技能库,大多数研究都默认了一个前提:有用的经验应当被完整地储存、检索和回放。为了让经验更具操作性,许多方法将其组织成带有明确接口和适用条件的程序化单元。人们理所当然地推断,经验表示得越完整、越结构化,对后续的任务求解就越有利。
但清华大学与EvoMap团队的研究,对上述假设发起了直接挑战。团队选取了一个涵盖45个复杂科学代码求解场景的基准库进行测试,任务跨度极大,包括蛋白质解析、紫外可见光谱峰值检测、系外行星凌日分析、地震目录处理、气候归因等多个高难度领域。

每次试验都在沙盒中执行生成的Python程序,并通过检查点机制严格评估准确度。以紫外可见光谱分析任务为例,模型需要读取数据、检测峰值、计算半峰全宽并输出结构化结果。常见的错误往往不在于模型缺乏高阶理解能力,而恰恰出在对底层代码库的调用细节上,比如将最小距离参数误当作波长值而非样本索引,或是忘记将宽度计算结果转换回波长单位。
传统的应对方式,是将这些历史教训整理成一份详尽的程序化技能文档,包含任务概述、工作流描述、辅助参考资料等,篇幅通常在2500个Token左右。这种形态高度贴合人类的阅读习惯,便于存档和知识转移。
然而,实验对比数据无情地打破了“文档至上”的神话。

上表展示了基础设定的测试结果。在无任何经验指导的基线设定下,平均通过率为51.0%。但当引入厚重的程序化技能文档后,双模型平均通过率不升反降,跌至49.9%。在Gemini 3.1 Pro Preview模型上,情况更为严峻,通过率从60.1%重挫至50.7%。这清晰地表明,一味堆砌经验内容,不仅无法转化为有效的控制信号,反而会对高能力模型产生严重的干扰。
剥离冗杂的技能包装
问题究竟出在哪里?研究团队进一步将臃肿的程序化技能文档拆解开来,试图找出其中真正起作用的控制信号。详尽的文档里,到底哪些内容对模型推理产生了正向引导?
拆解实验给出了一个残酷的答案:程序化技能文档内部的效用分布极度不均。
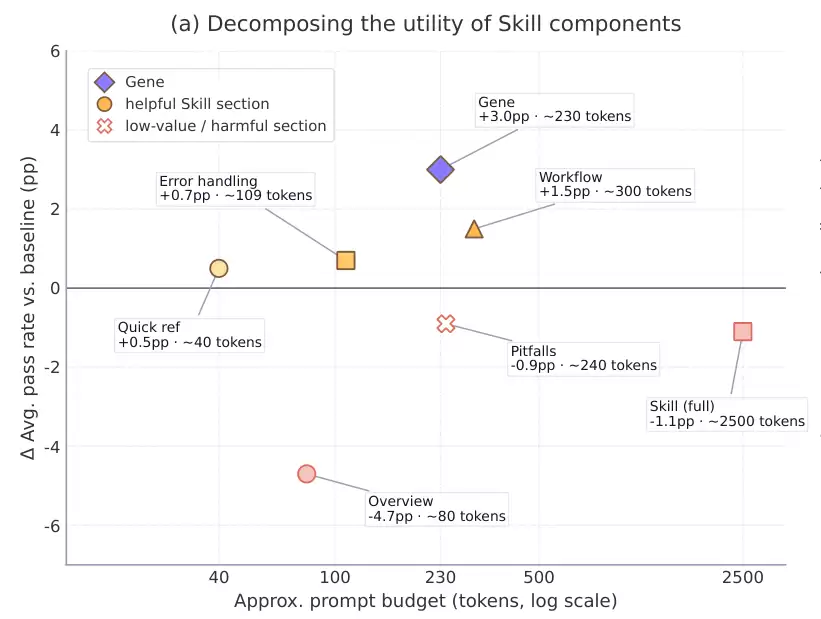
数据显示,仅有“工作流”部分能够带来明确的正向收益,而诸如“概述”等描述性段落则表现出强烈的负面影响。绝大部分文档内容,根本无法作为可执行的控制信号发挥作用。真正有价值的信号极其稀疏,且高度集中在极窄的操作指南切片中。
为了验证这一点,研究人员测试了在同等预算下的表现差异。将2500 Token的文档激进地裁剪至与后续“策略基因”相当的230个Token后,缩减版的片段表现确有回升,这在一定程度上证实了性能低迷确实源于“包装过载”。
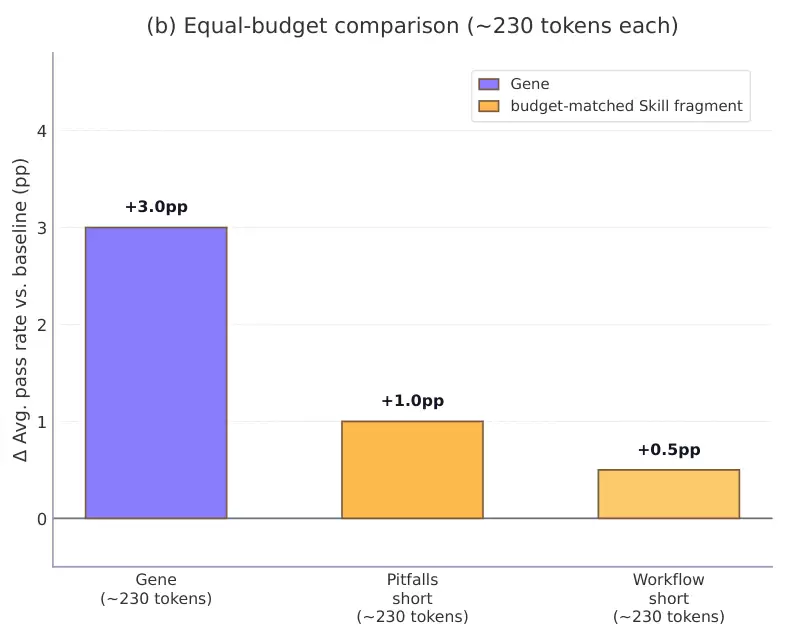
但即便如此,经过极限瘦身的缩减版技能,其表现依然全面落后于全新的“策略基因”。这揭示了一个核心缺陷:程序化技能的问题不在于缺失知识,而在于知识的呈现方式。长篇幅的文档确实包裹着有用信息,但高价值的指令信号被海量的说明性文字严重稀释了。从人类视角出发的详尽解说,在模型受限的推理预算和注意力分配机制下,彻底沦为沉重的认知负担。
策略基因的紧凑革命
那么,什么才是真正适合模型的经验载体?为了探索这个问题,研究团队引入了“策略基因”与“基因演化协议”这一全新框架。
策略基因是对过往经验的一次彻底抽象。它完全摒弃了对“文档完整性”的追求,将重心转向高密度的信号、清晰的适用边界和强烈的控制相关性。一个典型的策略基因实例仅包含极简的匹配关键词、简短摘要、核心策略步骤以及明确的回避警告。它舍弃了所有冗长的背景铺垫,直接向模型输出任务控制界面的关键参数。
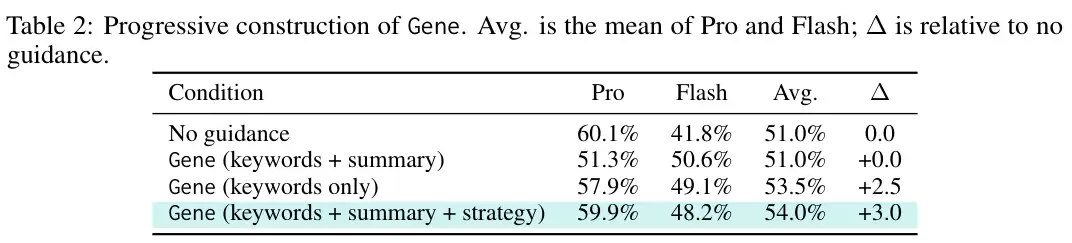
效果立竿见影。如上表所示,仅用230个Token的“基因组”,就将双模型平均通过率推升至54.0%,实现了3.0个百分点的绝对增长。它在Pro模型上保持了59.9%的高位,同时将Gemini 3.1 Flash Lite Preview的通过率从41.8%大幅拉升至48.2%。
为了探究其成功秘诀,研究团队逐步剥离并重组了策略基因的内部结构。纯关键词变体拿到了53.5%的成绩;增加摘要后表现平平;直到补齐完整的策略步骤,性能才达到巅峰的54.0%。这说明,单纯缩减字数并非制胜关键,真正的性能飞跃,发生在经验被凝练重组为清晰行动策略的那一刻。
抗干扰测试进一步揭示了策略基因的稳健性底色。
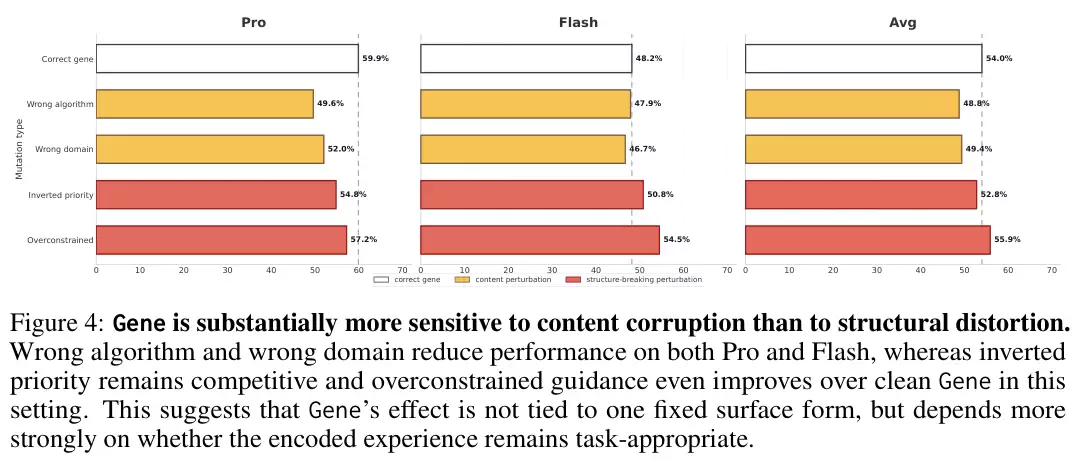
测试发现,如果人为替换错误的算法或填入毫不相干的领域信息,性能会瞬间雪崩,平均通过率跌落至48.8%和49.4%。然而,将策略优先级倒置或者添加过度限制的约束条件,对整体表现的破坏却微乎其微,“过度约束”变体甚至逆势升至55.9%。这意味着,只要核心策略内容与当前任务对齐,字面结构的轻微扭曲并不会摧毁其控制效力。
更有趣的是,试图将“基因”重新扩展回“技能”的尝试均告失败。
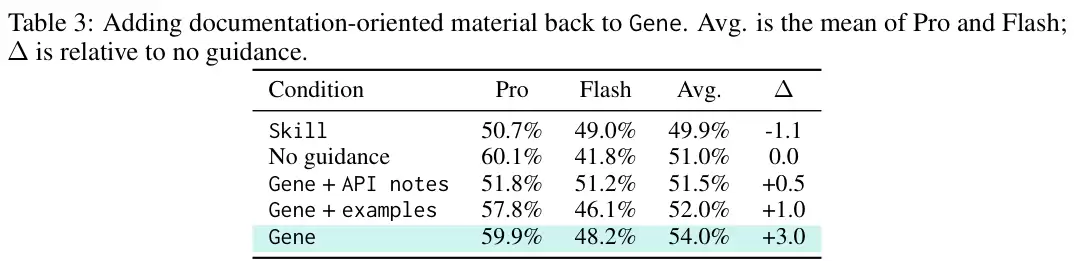
强行给基因附着额外案例或接口说明文档,非但无法形成互补,反而导致表现回落至52.0%和51.5%。这证明,面向控制的精简对象一旦被文档化材料“污染”,其指令纯度便会遭到破坏。
此外,多个基因片段的简单拼接也无法实现性能的线性增长。
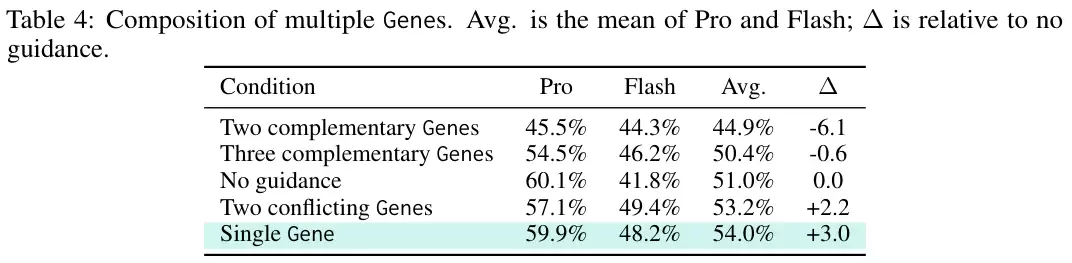
组合两个相冲突的基因,仍能保持53.2%的及格线;但凑齐两个看似互补的基因,成绩却直接垫底,降至44.9%。这在需要极高精度控制的科学场景中尤为致命:多个看似互补的控制对象会相互争夺模型的注意力,最终导致控制焦点彻底模糊。随心所欲的“技能袋”堆叠法,在严苛的科学评测面前宣告破产。
面向测试时演化的载体
单次推理验证了策略基因的威力,但智能体的学习是一个持续的过程。研究团队进而将视线投向更长周期的经验累积机制:智能体在不断的交互中必然会产生大量犯错记录,如何有效地挂载并消化这些“失败履历”,成为测试各种载体承载力的试金石。
对照数据给出了明确的指引。
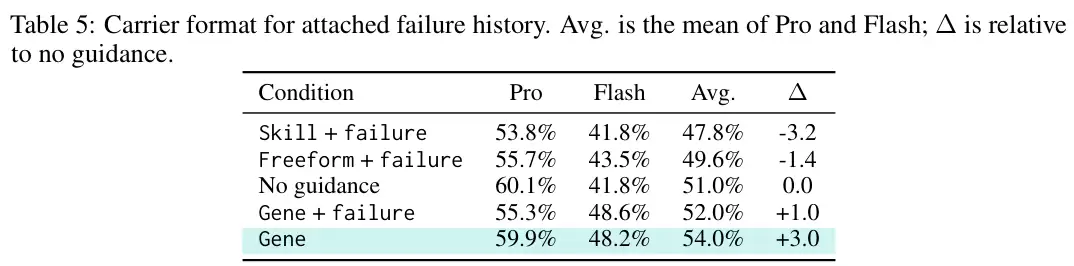
将失败历史强行塞入自由格式的文本中,平均成绩仅为49.6%。挂载到传统的程序化技能文档则引发了灾难性倒退,降至47.8%。而策略基因展现出了极强的包容性,以52.0%的成绩遥遥领先。载体格式的“基因优势”在此被再次确立。
值得注意的是,格式的规整程度直接决定了经验的转化效率。

当把高度结构化的基因打散为平铺直叙的散文后,其优势几乎荡然无存,平均成绩滑落至50.5%。这证明,规范的结构化协议,是维持控制效力的关键所在。
那么,新旧经验应该如何结合?实验表明,简单粗暴地拼接并不可取。
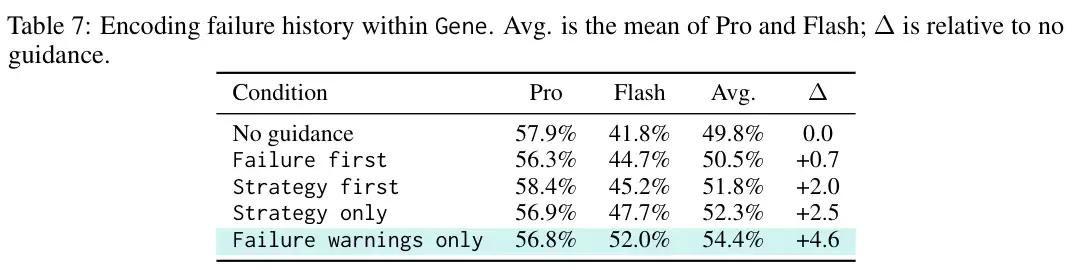
将失败记录原封不动地附加在策略基因之后,虽然跑赢了其他载体,但仍比纯净版基因落后2.0个百分点。提炼失败教训的最佳姿势,是将其压缩为简练独立的“警告信号”。纯粹的“失败警告”设定取得了54.4%的最佳战绩,一举击败了策略优先或失败优先的混合打包方案。这再次印证了一个核心原则:经验的累积应当时刻保持克制,精准压缩永远优于无脑扩容。
为了验证策略基因作为持续演化底座的潜力,研究团队在CritPt基准上部署了一套由OpenClaw运行环境与Evolver演化引擎驱动的基因演化系统。该系统围绕结构化的基因展开自我演化,通过记忆整合历史因果经验,并借助严格的验证机制固化成功更新。
演化结果呈现出令人惊叹的爆发力。
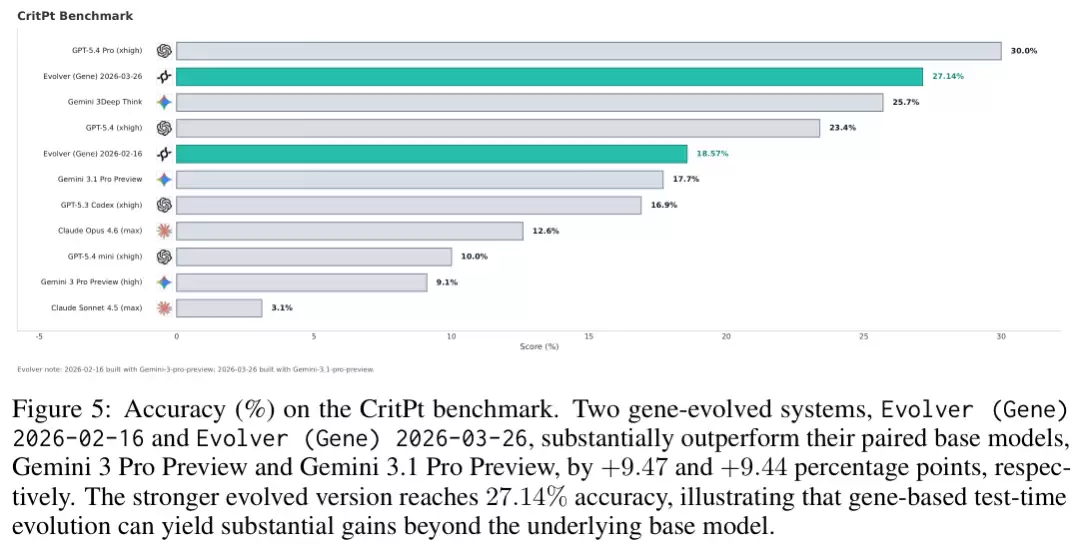
2026年2月版的早期演化体,通过高度专注的错误诊断、影响半径评估与最小可逆补丁的闭环,将Pro模型在特定任务上的准确率从9.1%拉升至18.57%。它成功将一次性的试错,内化为一条可无限复用的修复流水线。
一个月后迭代出的新演化体,进一步展现了探索增强的统治力。在70个复杂任务中,系统调用了210个基因槽位。例如,在哈密顿逆向设计任务中,一个被高频启用的核心基因抛弃了所有笼统的提示,直接罗列出对易关系、归一化条件与算符排序等刚性约束。它在维持索引一致性的前提下将复杂的多体链问题完美降解,最后通过严苛的符号与数值双重校验来保障数值稳定性。此类从成功履历中榨取出的“硬核”操作步骤被反复重用,最终一举斩获27.14%的超高准确率,彻底超越了基线水平。
这项研究揭示了一个深刻的洞见:从冗长的人类技能文档,到冷峻精简的策略基因,AI吸纳经验的方式必须化繁为简。唯有如此,才能摆脱信息过载的泥潭,释放出智能体真正的演化潜能。这不仅是技术路径的优化,更是一次思维范式的转变。
来源:互联网
本文内容整理自公开资料与网络信息,仅供学习和参考使用。正式发布或转载前,请结合原始来源、发布时间和实际场景进一步核验。
