视频物体移除是基础,那“物理交互移除”呢? 在视频编辑工具箱里,物体移除早已不是
在视频编辑工具箱里,物体移除早已不是什么新鲜事。目前的主流方法,应付那些“简单”场景已经游刃有余——比如干净地抹掉一个障碍物,把它背后的背景天衣无缝地补全,或者顺带消除它的影子和倒影,都不在话下。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
但真正的挑战往往藏在更复杂的现实里:如果要移除的物体,并非孤立存在,而是与场景中的其他元素有着实实在在的物理交互,该怎么办?
不妨设想两个场景:一排多米诺骨&牌正连锁倒下,如果凭空移除中间几块,按照现有逻辑,后面的骨&牌理应继续倒下。但这在物理上根本讲不通,因为推动它们的“前因”已经消失了。再比如,画面里有一双手正在转动陀螺,倘若移除这双手,物理规律告诉我们,陀螺会依靠惯性继续旋转,而不是随之凭空消失或骤然停止。
这类场景对模型提出了更高要求:它不能只做“擦除”和“修补”,还必须具备一定的因果推理能力。核心问题是,不仅要“移除”物体本身,还得推演“如果这个物体从未存在过,整个场景的物理进程会如何演变”。而这,正是当前许多视频编辑模型的盲区。
面对这个瓶颈,Netflix(网飞)团队与合作伙伴给出了他们的答案:“视频目标与交互删除”框架,简称VOID。

论文链接:https://arxiv.org/pdf/2604.02296
VOID的目标很明确:不仅要移除指定目标,还得对其消失后可能引发的物理连锁反应,进行合理建模与生成。框架的基石是三大核心创新:利用物理仿真引擎构建反事实数据集、引入交互感知的“四值掩码”作为条件化策略,以及在推理时借助视觉-语言模型自动识别哪些区域会受影响。
值得一提的是,VOID基于智谱AI的视频生成模型CogVideoX构建,并专门针对具备交互感知掩码条件的视频修复任务进行了微调。
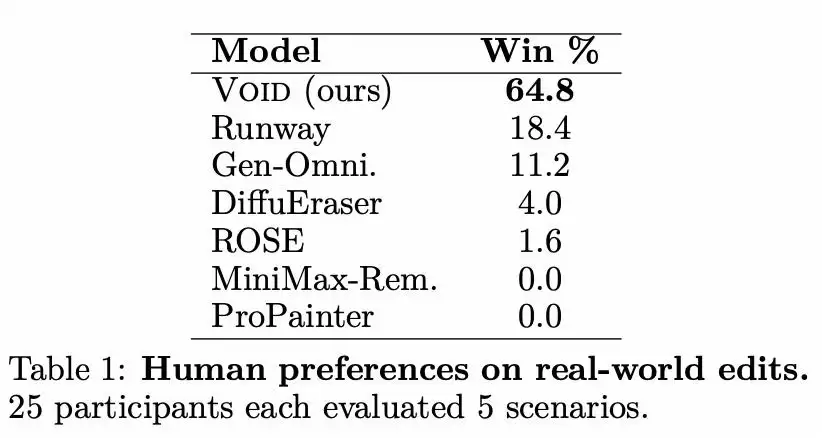
效果如何?研究数据给出了有力证明:在人类偏好评估中,VOID结果被选为最优的比例高达64.8%,远超第二名Runway的18.4%。
更令人印象深刻的是其泛化能力。VOID能处理许多训练数据中从未出现过的物理效果,例如“移除拿着气球的玩具熊后,气球会向上飘走”,或者“移除按下搅拌机按钮的人手后,搅拌机保持静止”。这表明,模型并非简单记忆样本,而是学会了调用底层模型的物理直觉进行推理。
整体而言,这项工作为视频编辑模型向更高阶的“世界模拟器”迈进,提供了扎实且富有启发的路径。
VOID的架构建立在CogVideoX的DiT骨架上,并从Generative Omnimatte的预训练权重初始化,从而继承了其对物体与效果进行分层解耦的优良能力。
在此基础之上,研究团队通过反事实数据对和独特的四值掩码进行微调,教会模型一个关键技能:在物体被移除后,如何生成物理层面合理的新运动轨迹。
整个过程可以概括为:用户提供一段视频并指定要移除的物体,系统随后自动推理哪些区域会因该物体的消失而产生变化,最终生成一段符合物理规律的反事实视频。
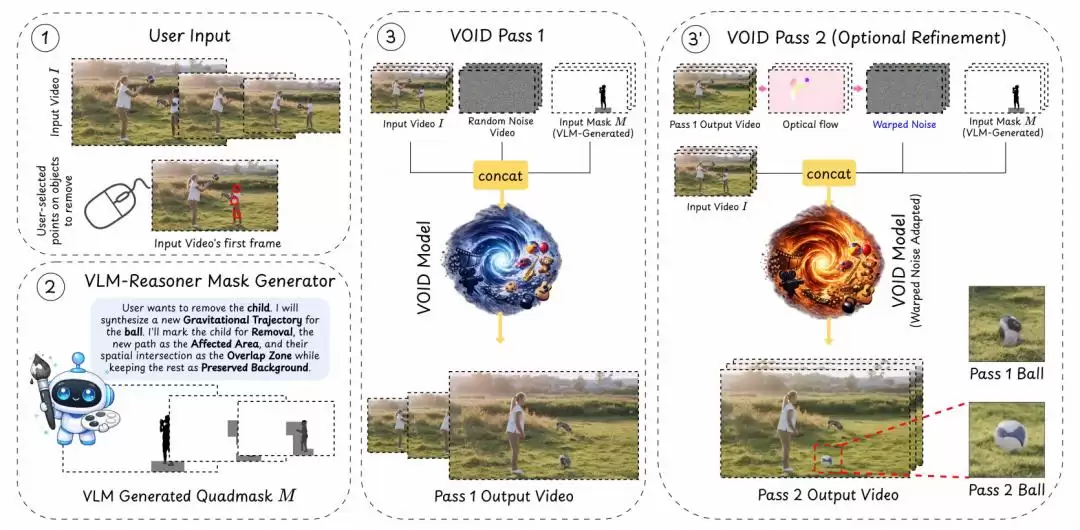
图|VOID 示意图
在推理阶段,用户的操作极其简单——只需点击目标物体。接下来的复杂分析交由系统完成:视觉-语言模型会解析整个场景,自动推断哪些物体会受到影响,以及它们在反事实场景中应该出现的位置。具体流程分四步走:
首先,VLM接收视频和物体掩码,输出一个受影响物体的描述列表。
接着,使用SAM 3模型对这些受影响物体进行分割,获取它们在原始视频中的位置掩码。
然后,在视频上叠加一个空间网格,由VLM预测这些物体在“假设目标不存在”的新场景中,最可能出现的位置。
最后,合并原始位置和预测新位置两组掩码,生成最终指导模型生成的“四值掩码”。
基于生成的四值掩码,VOID通过两阶段推理来打磨最终结果。
第一阶段:反事实轨迹合成。 模型根据输入视频和四值掩码,生成一个初步的反事实预测。这一阶段能抓住大方向正确的运动假设,比如失去支撑的物体开始自由落体。但由于视频扩散模型在生成复杂运动时,偶尔会出现物体变形或闪烁的问题,因此需要进一步优化。
第二阶段:光流引导的噪声稳定。 受“Go-with-the-Flow”方法的启发,VOID从第一阶段输出中提取光流场,并用其生成与时间序列相关的扭曲噪声,将此作为第二阶段的输入。这相当于让扩散模型沿着正确的运动轨迹进行一致性的去噪,从而显著减少物体变形。是否需要触发第二阶段,由VLM自动判断——通常只在检测到场景存在大幅动态变化时才会启用。
无论是在真实数据还是合成数据上的实验,结论都指向一点:与现有的视频对象移除方法相比,VOID在移除对象后,能更出色地保持整个场景动态的连贯性与物理合理性。
评估真实世界视频没有“标准答案”,因此研究团队采用了多维度的评估方式。
人类偏好研究: 25名参与者每人评估5个不同场景,从7个模型的输出中挑选最佳结果。数据显示,VOID以64.8%的胜率稳居第一,达到SOTA水平。值得注意的是,即使竞争对手Runway额外接受了描述预期场景变化的文本指令,仍未能撼动VOID的优势。
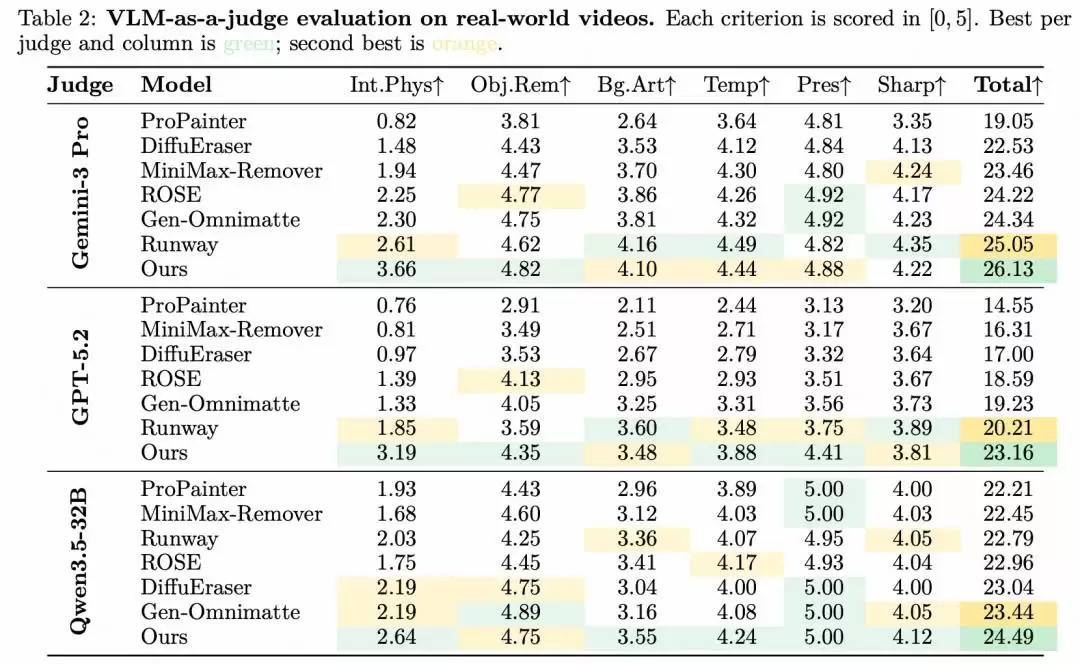
VLM裁判评估: 团队还请来了Gemini 3 Pro、GPT-5.2和Qwen 3.5-32B三位VLM“裁判”,从交互物理合理性、物体移除质量、时序一致性、场景保留度等多个维度进行自动评分。在全部三位裁判的评选中,VOID均获得了最高的总分。尤其在衡量核心能力的“交互物理”维度,优势更为突出:在Gemini 3 Pro的评估中,VOID得分3.66,而第二名Runway仅为2.61。
定性对比: 在众多真实场景案例中,基线方法暴露出各种不足:在碰撞场景中未能正确移除物体、重物移走后枕头依然保持凹陷、移除油漆滚筒后墙上却出现了新油漆等。反观VOID,在所有测试案例中都表现出了正确的物理推理。

对未见效果的泛化: 在泛化能力测试中,VOID成功处理了多种训练时未曾见过的交互类型。例如:移除拿着气球的卡通熊后,气球会向上飘走;移除按下搅拌机按钮的孩子后,搅拌机保持未启动状态;移除正在咬住棍子的狗后,棍子自然掉落;以及移除作为障碍物的橡皮鸭后,小球的滚动轨迹随之改变。

在一个包含10个经典影子/倒影移除案例和30个动态交互案例的合成基准测试上,VOID同样展现了SOTA级别的能力。
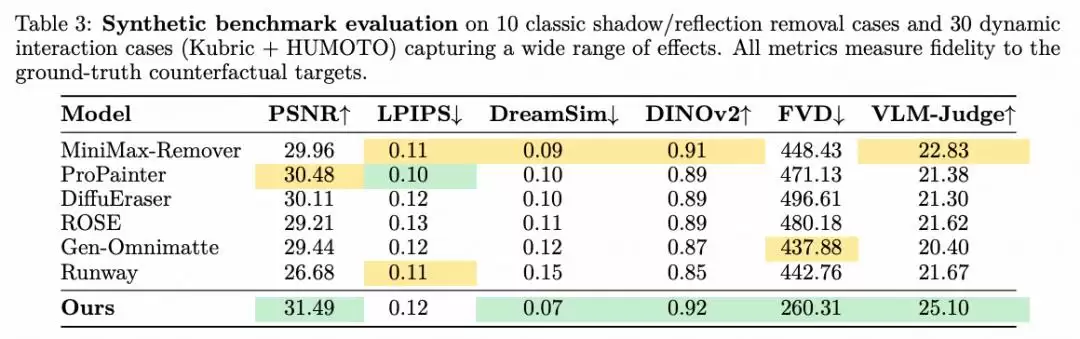
在除LPIPS之外的所有评估指标上,VOID均取得了最佳成绩。这里有个有趣的细节:LPIPS指标对局部像素位移非常敏感。这意味着,如果模型正确模拟了物体掉落,但下落速度与“标准答案”有细微偏差,其得分反而可能低于那些简单删除物体、导致物理错误的模型。而在更能衡量整体质量的视频级指标(如FVD)和VLM裁判分数上,VOID与基线模型的差距最为显著,这强有力地证明了其在物理合理性与语义一致性方面的卓越优势。
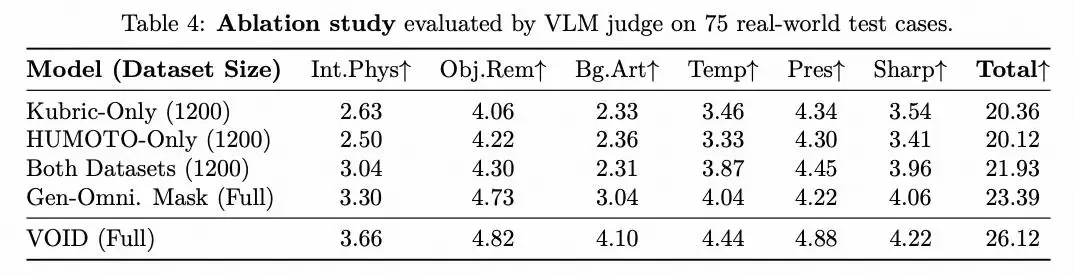
此外,在75个真实世界测试用例上进行的消融研究进一步表明:混合不同来源数据集带来的多样性(即使总数据量不变),其效果优于使用单一数据源;同时,精细的四值掩码配合VLM引导的生成流程,其效果也明显胜过粗糙的全局掩码策略。
尽管VOID展现了强大的潜力与泛化能力,但这项研究也客观地指出了当前的一些局限性:
域差距问题: 当测试视频的拍摄角度比较异常,或者摄像机过于靠近物体时,模型的性能会出现下降。
数据来源局限: 目前的训练数据全部来自计算机渲染引擎,未来可以探索结合更多样化的真实世界数据获取方式。
视频长度和分辨率: 当前生成视频的长度仍限制在几秒钟,分辨率也有进一步的提升空间。
研究团队展望,随着更强大的视频生成模型和视觉-语言模型不断涌现,这一框架的性能有望持续提升。更重要的是,这项工作揭示了一个充满趣味且远未充分探索的方向:如何将强大的世界建模与物理推理能力,有效地迁移并应用于视频编辑这一实用领域。这或许才是其最令人期待的价值所在。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。

































