PostgreSQL 的进化之路:从 PG 18 的“真香”特性到 PG 19 的未来前瞻 PostgreSQL 的每一次大版本
PostgreSQL 的每一次大版本更新,都像一场技术盛宴,总能带来一些令人眼前一亮的突破。从去年发布的 PG 18 到即将到来的 PG 19,新特性接踵而至——异步 I/O 为云上性能插上翅膀,内核级 REPACK 直击表膨胀的顽疾,图查询能力则为 AI 时代铺平了道路。但面对如此多的更新,哪些特性真正值得投入关注?企业又该如何规划升级路径?更重要的是,如何参与到这个充满活力的开源生态中?
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
在 HOW 2026(开源生态大会暨 PostgreSQL 高峰论坛)上,我们与三位深耕 PostgreSQL 多年的技术专家——IvorySQL 专家顾问委员、PostgreSQL ACED、前阿里云数据库高级专家德哥,云和恩墨高级数据库技术顾问、IvorySQL 专家顾问委员彭冲,以及 PostgreSQL ACE、PG 分会西安用户组主席、公众号「PostgreSQL 运维之道」主理人杨向博——进行了一场深度对话,由墨创数迹创始人汪丹(Yolanda)主持。本文将为你梳理其中的核心洞察,解读 PG 18 的实用价值,前瞻 PG 19 的重磅更新,并分享企业升级策略与社区贡献的实战指南。
核心观点先览:
1. PostgreSQL 的大版本发布从不令人失望。它并非简单的修修补补,而是包含众多能真实解决生产痛点的亮眼特性。
2. PostgreSQL 的进化路径务实而独特。社区以严苛的标准保障稳定性,通过丰富的插件生态先行验证需求,最终将成熟方案收敛至内核。这保证了其既不会为了追求新特性而牺牲稳定,也不会因保守而拒绝变革。
3. 从 PG 18 的异步 I/O、统计信息保留,到 PG 19 的内核级 REPACK 和图查询支持,我们看到了一个面向云原生与智能时代持续演进的数据库未来。
4. 企业升级,没有“最好”的版本,只有“最合适”的版本。关键在于是否为解决真实痛点而升级。
5. PostgreSQL 社区开放且包容,贡献方式多种多样。从报告 Bug、编写插件、分享文章到提交内核代码,每一个声音都能推动 PostgreSQL 向前进化。
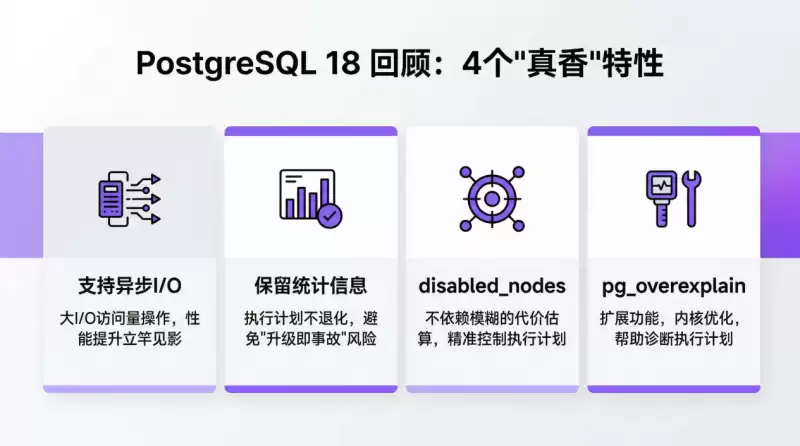
让德哥首先点赞的,是 PG 18 对异步 I/O 的支持。这个特性为何关键?如今,数据库部署在云端已是常态,但云上环境与本地部署有本质不同。本地 SSD 的 I/O 延迟通常在微秒级,而云盘需要通过网络访问,延迟显著增加。在 PG 18 之前,像创建索引、垃圾回收(VACUUM)、大表全量扫描这类涉及大量 I/O 的操作,都采用同步 I/O 模式,数据库进程大量时间耗费在等待网络 I/O 返回上。
PG 18 引入的异步 I/O 子系统彻底改变了这一局面。它允许进程在发起 I/O 请求后不必等待,可以继续处理其他任务,从而极大地提升了高并发、大 I/O 场景下的吞吐量。对于云上数据库而言,这堪称性能的“游戏规则改变者”。
德哥分享的第二个特性,关乎大版本升级的平滑性。对于需要频繁升级的云厂商或企业来说,这尤其有价值。传统上,大版本升级主要有两种方式:逻辑复制和 pg_upgrade。逻辑复制对表结构有要求(如需要主键),且切换时存在数据不一致风险;而 pg_upgrade 虽然快捷,却有一个长期被诟病的缺点——无法保留优化器统计信息。
这意味着,升级完成后,数据库的查询优化器如同“盲人摸象”,很可能生成错误的执行计划。若恰逢业务高峰,大量非最优查询涌入,极易引发性能雪崩。PG 18 终于解决了这个痛点,它支持在 pg_upgrade 过程中保留统计信息,确保升级后执行计划的准确性,让“平稳升级”从理想变为现实。
杨向博则提到了一个容易被忽略但对 DBA 至关重要的特性:disabled_nodes。SQL 执行计划“跑偏”是 DBA 的日常烦恼。对于无法修改 SQL 的 SaaS 类应用,通常使用 Hint 来干预优化器选择。但在 PG 17 及之前,是通过一个名为 disable_cost 的粗暴机制来实现的——给不希望的执行路径加上一个巨大的代价常量(100亿)。
这种方式存在明显缺陷:当多个路径都被加上这个天文数字后,它们之间的实际代价差异被掩盖,可能导致优化器反而选出更差的计划。PG 18 果断摒弃了 disable_costdisabled_nodes。其原理是为一个被禁用的路径节点标记一个整数值(默认为0,禁用则加1),该值会在执行计划树中向上传递。这样,优化器可以清晰比较不同路径被干预的程度,实现对执行计划的精准、可控干预。
彭冲补充了另一个与执行计划相关的利器:pg_overexplain 扩展。这是一个 PG 18 引入的扩展功能,它的作用是以一种更结构化、更深入的方式,揭示查询优化器内部的决策细节。如果说传统的 EXPLAIN 输出是执行计划的“体检报告”,那么 pg_overexplain 就是一份详尽的“病理分析”。它帮助开发者深入内核层面,诊断复杂查询的性能瓶颈,是进行深度 SQL 调优和内核研究的强大工具。
尽管 PG 19 即将发布,但生产环境中 PG 16、PG 17 仍是主流。毕竟,稳定压倒一切。那么,企业究竟该如何决策升级时机?三位专家结合典型场景给出了具体建议:
场景一:云部署 + 大 I/O 操作
· 痛点:数据库部署在云盘上,且频繁进行索引创建、垃圾回收、大规模分析查询等操作。
· 建议:升级至 PG 18。异步 I/O 特性将带来显著的性能提升。
场景二:表膨胀困扰
· 痛点:某些表频繁膨胀,导致存储成本攀升,查询性能下降。
· 建议:等待 PG 19。其内核集成的 REPACK 功能将提供比外部工具更稳定、更可靠的表空间重整方案。
场景三:信创需求 + 跨 CPU 架构迁移
· 痛点:有信创背景需求,需要在 ARM 与 x86 等不同架构服务器间进行流复制或数据迁移。
· 建议:升级至 PG 17 或 PG 18。这些版本提供了更好的跨架构字符比较与排序兼容性处理,让迁移更平滑。
场景四:AI 应用与知识图谱
· 痛点:正在构建 AI Agent 应用,需要存储记忆或知识图谱;目前需单独维护图数据库,数据同步复杂。
· 建议:等待 PG 19。原生图查询能力的引入,将实现关系型与图数据模型的统一,极大简化技术栈。
当然,实际挑战远不止这些,例如逻辑复制可能引起的磁盘堆积、数据库快速拷贝的需求、外部表的安全增强等。核心原则是:根据自身业务的具体痛点,去匹配 PostgreSQL 版本所提供的核心能力。
德哥对此总结了一个清晰的思路:对于业务迭代相对平缓的传统企业,不必急于追新。当现有版本的某个痛点已严重影响业务,而新版本能完美解决时,才是升级的最佳时机。反之,对于业务变化极快的互联网或创新型企业,则可以更积极地采用新特性(如 PG 19 的图查询)来构建竞争优势,升级策略可以更偏激进。
PostgreSQL 社区以其开放、友好和包容著称。如何从一名使用者转变为贡献者?专家们分享了从易到难的贡献路径:
1. 从报 Bug 开始:这是最直接的贡献方式。关键在于按照社区模板,清晰、完整地提交问题报告,包括版本、操作系统、复现步骤等。信息越详细,修复效率越高。
2. 编写插件:直接参与内核开发门槛较高,但 PostgreSQL 强大的扩展性提供了绝佳的切入点。当你有一个好点子,或遇到某个可用插件解决的问题时,尝试动手写一个。利用好现代开发工具(包括 AI 辅助编码),从巡检脚本、实用工具(Skills)开始,让想法落地。许多内核功能最初都源于成熟的插件。
3. 文章分享:不要低估经验分享的价值。将故障排查过程、性能优化心得、对某个特性的深度解读整理成文,能帮助无数同行少走弯路,这也是极其宝贵的贡献。
4. 内核贡献三步法:若志在核心代码,可以遵循以下路径:
第一步,观察学习:订阅邮件列表,阅读过往讨论,了解社区的沟通风格、代码规范和流程。
第二步,小处着手:从社区的 Bug List 中挑选一个明确、具体的小问题开始解决,积累信心和经验。
第三步,大胆提交,坦然面对反馈:PostgreSQL 社区对新人格外友好,但代码审查也以严苛著称。提交补丁后,被要求修改甚至拒绝都是常态,每一次反馈都是深入学习内核设计的宝贵机会。
从 PG 18 到 PG 19,我们看到的不是激进的技术冒进,而是一种务实的进化哲学:每一个特性都经过充分讨论与验证,在确保稳定性的基石上,将经过插件生态检验的最佳实践逐步收敛至内核。这种“在稳定中创新”的节奏,或许正是 AI 时代复杂系统演进所需要的智慧。PG 19 将成为一个新的起点,未来,关于数据库的更多可能性与更激动人心的篇章,正等待整个社区共同书写。
4 月 27 - 28 日,HOW 2026 开源生态大会暨 PostgreSQL 高峰论坛将在济南举行,1 场主论坛与 12 大主题分论坛将全方位展现 PostgreSQL 的技术版图与未来展望。欢迎报名参加,与我们一同探讨。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。