AI视频生成领域长期存在一个软肋 说来有意思,AI视频生成技术发展至今,一直有个让人头
说来有意思,AI视频生成技术发展至今,一直有个让人头疼的“老大难”问题:单看一个镜头,画面往往惊艳四座,可一旦想让AI讲一个稍长的故事,画面崩坏几乎成了逃不掉的宿命。前一秒主角还在咖啡馆里喝咖啡,下一秒可能就毫无征兆地瞬移到了火星表面,更离谱的是,连角色的长相都可能彻底换了个——这故事还怎么讲得下去?
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
终于,针对这个顽疾,最近行业里扔下了一枚重磅冲击波。字节跳动与南洋理工大学联手,推出了开源框架StoryMem。这可不只是一次普通的技术修补,它更像是给算法装上了某种类似人类的“长期记忆”能力。有了它,AI才算真正摸到了驾驭长镜头、构建电影级叙事的大门。
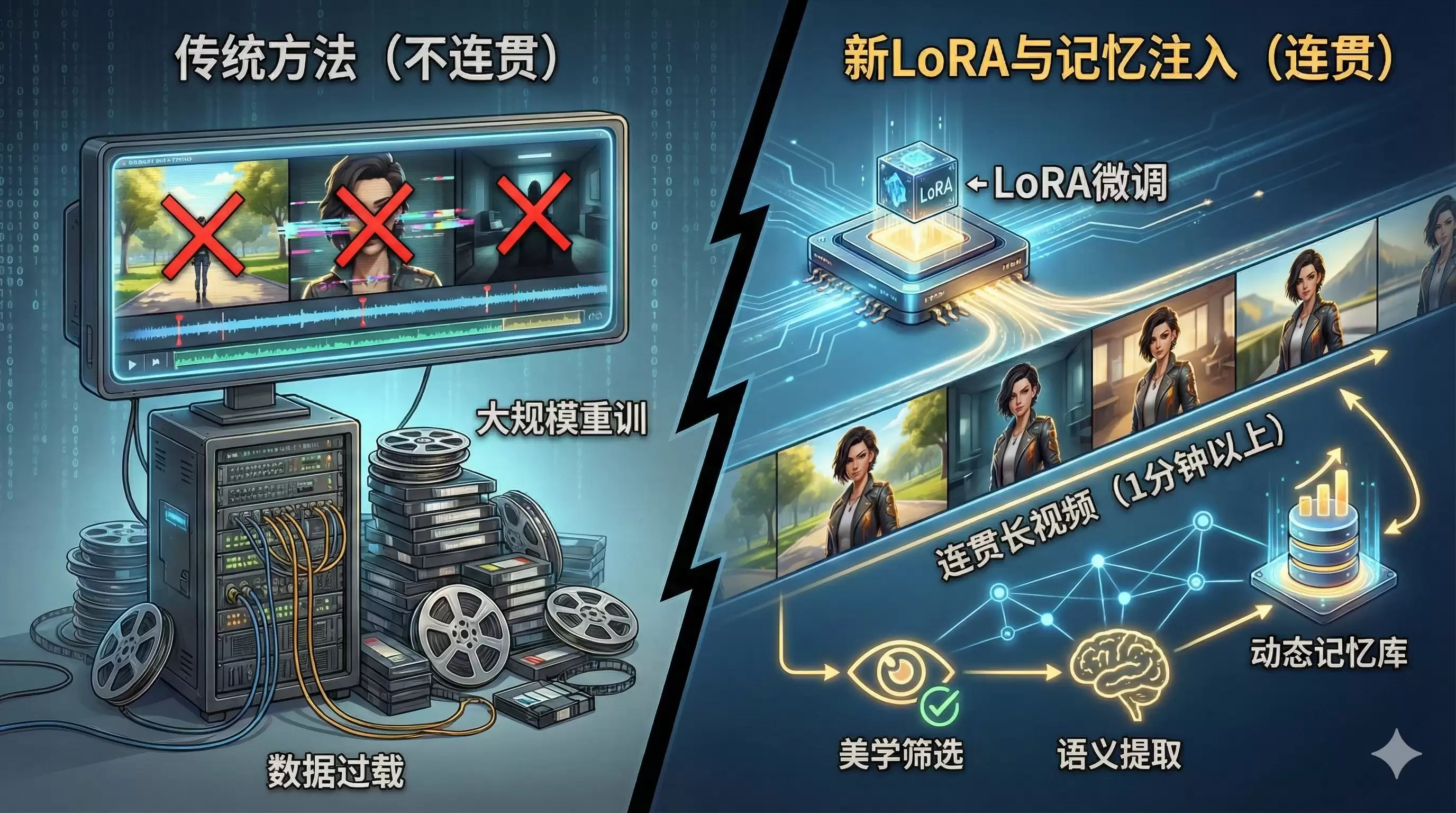
StoryMem的魅力,源于其独创的M2V设计理念。这么说吧,传统的视频生成模型,有点像一位患有严重健忘症的画家。每画完一幅画,就把前一张的内容忘得一干二净,结果每一帧都精美,但连起来却前言不搭后语。
而StoryMem的解决方案很巧妙:它给AI配备了一个精巧的动态记忆库。流程是这样的:当第一个镜头根据文本描述生成后,系统会立刻从中提取出关键帧的视觉信息,并将其“封存”入这个记忆库中。重点来了——此后每一个新镜头的生成请求,都会触发一个叫做M2V LoRA的特殊模块介入。这个模块扮演着“严苛监工”的角色,它的任务就是强制将记忆库里的视觉特征,“注入”到当前正在工作的扩散模型中去。这样一来,新生成的画面就不得不与之前的镜头保持逻辑上的强关联。

这种机制的改变是碘伏性的。它最大的优势在于,不再需要耗费巨资去搜集海量的长视频数据来重新训练整个模型,仅仅通过轻量级的LoRA微调,就能让AI学会“连戏”。经过记忆的注入与约束,无论是角色服饰的纹理细节、面部特征的微妙表情,还是场景的光影氛围与整体风格,都能在长达一分钟甚至更久的视频序列中,保持惊人的一致性。那个长期困扰业界的“角色变脸”和“场景跳变”难题,在这里找到了极佳的解题思路。
更智能的是,系统还会自动对新生成的画面进行美学质量筛选和核心语义提取,并以此不断更新和优化记忆库的内容。这意味着,故事不仅开头稳,还会随着讲述的推进“越讲越顺”。
那么,实际效果到底怎么样?数据是最直接的答案。在与现有主流方法的对比测试中,StoryMem在“跨镜头一致性”这个核心指标上,实现了高达29%的显著跃升。这个数字意味着,生成的视频终于摆脱了碎片化堆砌的观感,具备了真正连贯、统一的质感。
值得注意的是,它在实现这一突破的同时,还完美继承了如Wan2.2等优秀基础模型的高画质基因,并且对用户提示词的理解异常精准。无论是自然的场景转场,还是复杂的推拉摇移运镜,处理起来都游刃有余。为了更全面地验证其能力,研发团队甚至专门构建了一套包含300个复杂场景的“ST-Bench”基准测试集。这一举动,摆明了是要在长叙事视频生成这个赛道上,树立一个全新的、更严格的评价标杆。

对于产业界而言,StoryMem的出现,无异于一场即将发生的生产力革命。
在广告与营销领域,创意人员可以将抽象的文案脚本,迅速转化为生动的动态分镜,低成本地进行多版本A/B测试,大幅提升创意决策效率。对于影视制作团队而言,它可以成为快速预览故事板视觉效果的强大工具,将前期漫长的沟通和修改成本压缩到最低。
而对于数量庞大的独立创作者和短视频博主来说,这更是一把打破高技术壁垒的利器。单枪匹马制作出剧情连贯、角色统一的叙事短片,从此不再是遥不可及的天方夜谭。
令人兴奋的还有开源社区的活力。项目正式上线仅仅几天,全球的技术极客们就已经开始探索其本地化部署的路径,部分开发者甚至在ComfyUI这类流行的图形化工具中,搭建出了初步的工作流。这意味着,这项听起来颇具前沿感的技术,正以惊人的速度“飞入寻常百姓家”,演化成每个人都能触手可及的创作工具。可以预见,一场基于“记忆”的视觉叙事浪潮,才刚刚开始。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。