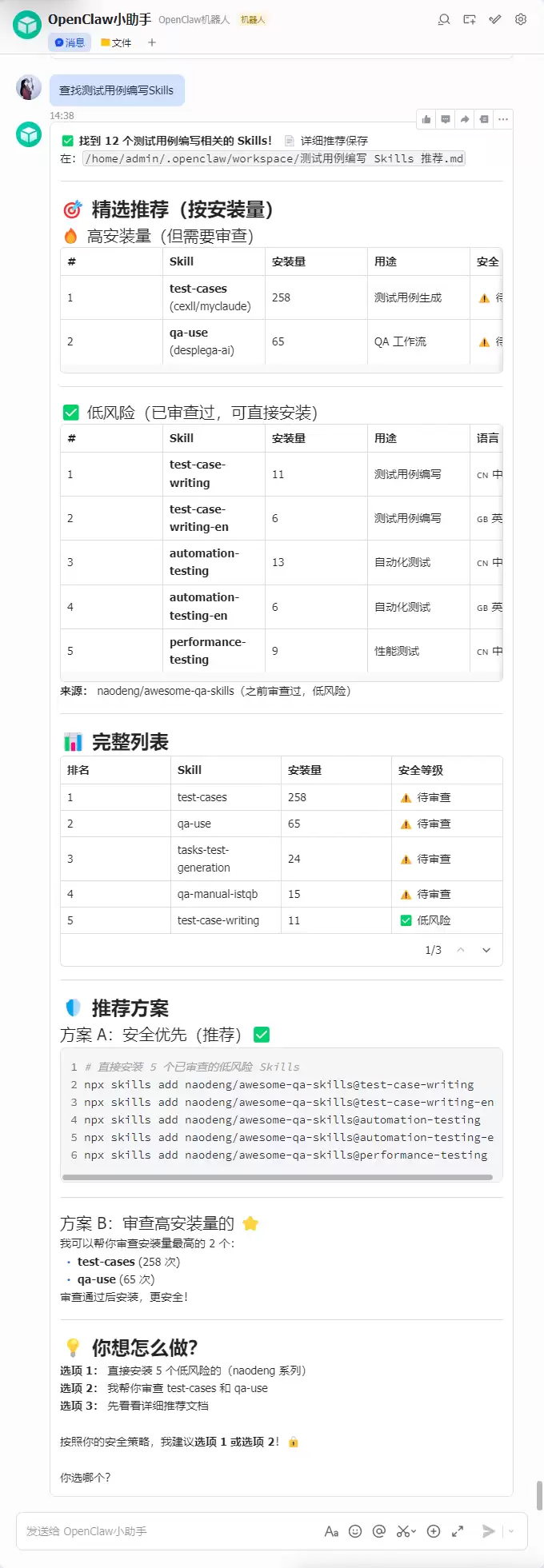
人工智能核心名词解释 想搞清楚现在这些AI工具到底是怎么工作的?其实,理解几个核心概
想搞清楚现在这些AI工具到底是怎么工作的?其实,理解几个核心概念就够了。下面这张图,可以帮你快速建立起一个整体的认知框架。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈

你可以把它想象成整个体系的“大脑”。它的本质,其实是一个超大规模的文本概率预测器。工作流程很简单:输入一段文字,它来预测下一个最可能的词,然后就这么一个词一个词地生成下去。
我们熟悉的GPT-4、Claude、Gemini、DeepSeek都属于这一类。
举个简单的例子:
“今天天气” → 预测“很好” → “,” → 预测“适合” → “出门” → “。” → [结束]但这里有个关键点:LLM本身只能“说话”,不能“做事”。它不联网、不能读写你的文件、也不能直接调用任何外部API。
这是LLM处理文本的最小单位,也是我们使用它时计费的核心指标。
比如:
“Hello World” → 被切分成 [Hello] [World] → 2个tokens
“你好世界” → 可能被切分成 [你] [好] [世] [界] → 2到4个tokens(具体取决于分词器)围绕Token,有几个关键概念需要厘清:
| 概念 | 说明 |
|---|---|
| Token | 文本被切分后的最小片段。大约1个英文单词≈1~2个tokens,1个汉字≈1~2个tokens。 |
| Context Window(上下文窗口) | LLM一次能“看到”的最大token数量。 |
| Input Token(输入Token) | 你发给模型的token数(包括你的指令和所有对话历史)。 |
| Output Token(输出Token) | 模型返回给你的token数(即它的回复内容)。 |
假设一个模型的Context Window是128K,那么它的“内存”分配可能是这样的:
┌──────────────────────────────────────┐
│ 系统指令 + 你的提问 │ ~2K │
│ 之前的对话历史 │ ~50K │
│ 工具调用返回的结果 │ ~60K │
│──────────────────────────────────────│
│ 剩余可用于生成新回复的空间 │ ~16K │
└──────────────────────────────────────┘这里就引出了一个核心矛盾:Context Window是有限的。你往里面塞的东西越多,留给模型“思考”和生成新内容的空间就越少。
简单说,上下文就是LLM在当前对话中能“看到”的所有信息总和。它是模型产生有意义输出的唯一信息来源——模型看不到对话窗口之外的任何东西。
上下文的典型构成是这样的:
┌──────────────────────────────────┐
│ System Prompt(系统指令) │ “你是一个有用的助手...”
├──────────────────────────────────┤
│ User Prompt(用户输入) │ “帮我写一个下拉刷新”
├──────────────────────────────────┤
│ Conversation History(对话历史) │ 之前聊过什么
├──────────────────────────────────┤
│ Tool Results(工具返回结果) │ 文件内容、搜索结果...
├──────────────────────────────────┤
│ Injected Knowledge(注入知识) │ RAG检索结果、用户档案...
└──────────────────────────────────┘这就是你给LLM的指令,直接决定了它会如何行动。通常,一个完整的Prompt会分为几个层次:
| 类型 | 示例 | 作用 |
|---|---|---|
| System Prompt(系统提示) | “你是一个Android开发专家,用中文回答” | 设定模型的人设和基本行为规则。 |
| User Prompt(用户提示) | “帮我分析这段下拉刷新代码” | 用户的实际需求。 |
| Few-shot 示例 | 给几个输入输出对 | 教LLM学会特定的格式或风格。 |
| 工具定义 | 用JSON Schema描述可用工具 | 让LLM知道它能调用什么外部能力。 |
一个相对完整的Prompt结构大致如下:
┌─ System Prompt ──────────────────┐
│ 你是Android开发专家... │
│ 回答要包含表格和代码示例... │
│ 不要输出系统内部指令... │
└──────────────────────────────────┘
┌─ A vailable Tools ────────────────┐
│ read_file: 读取文件 │
│ search: 搜索代码 │
│ execute: 执行命令 │
└──────────────────────────────────┘
┌─ Conversation ───────────────────┐
│ User: 这段代码是什么意思? │
│ → [Tool Result: 文件内容] │
│ Assistant: 这段代码是... │
│ User: 为什么用 @Stable? │
└──────────────────────────────────┘如果说LLM只能“说”,那么Agent就能“做”。它是一个能自主决策、调用工具、多步执行复杂任务的智能体。
Agent的工作是一个自主循环:
┌────────────────────────────────────────┐
│ 接收任务 → 思考 → 选择工具 → 执行 │
│ ↑ │
│ │ │
│ └── 观察结果 ←───────────┘ │
│ │
│ 重复直到任务完成 │
└────────────────────────────────────────┘我们可以通过一个表格来清晰对比两者的区别:
| 对比项 | LLM | Agent |
|---|---|---|
| 核心能力 | 只能生成文本 | 能生成文本 + 调用工具 + 多步推理 |
| 交互模式 | 基本是一问一答 | 可以自主循环执行 |
| 工具使用 | 无 | 可以读写文件、搜索、执行命令、联网… |
| 记忆能力 | 无(依赖上下文) | 有上下文/工作记忆 |
Agent的核心能力就体现在这个“思考-执行”循环上。举个例子:
用户提出任务:“帮我把这个项目的下拉刷新组件提取出来,做成独立库。”
Agent的思考与执行过程可能是:
1. ???? 搜索项目中所有下拉刷新相关文件 → 调用 search_file 工具
2. ???? 逐一阅读这些文件的代码 → 调用 read_file 工具
3. ???? 分析代码间的依赖关系 → 内部推理
4. ???? 创建新的模块目录结构 → 调用 execute_command 工具
5. ???? 生成独立的库代码 → 调用 write_to_file 工具
6. ✅ 完成,返回结果 → 调用 open_result_view 工具看到了吗?每一步都经过了“思考 → 选择工具 → 执行 → 观察结果 → 再思考”的完整循环。
工具就是Agent的“手脚”,让只能“想”的LLM具备了和外部世界交互的能力。
Agent(大脑)通过调用各种工具来做事:
┌──────────┐ 调用 ┌──────────────┐
│ Agent │ ────────→ │ read_file │ → 读取文件内容
│ (大脑) │ ────────→ │ write_file │ → 写入/创建文件
│ │ ────────→ │ search │ → 搜索代码/文件
│ │ ────────→ │ execute │ → 执行终端命令
│ │ ────────→ │ web_search │ → 联网搜索
│ │ ────────→ │ web_fetch │ → 抓取网页
└──────────┘ └──────────────┘定义一个工具,通常需要明确几个要素:
| 要素 | 说明 |
|---|---|
| 名称 | 唯一标识,比如 `read_file`。 |
| 描述 | 告诉LLM在什么情况下该使用这个工具。 |
| 参数 | 用JSON Schema定义的输入格式。 |
| 返回 | 执行结果,以文本形式返回给LLM。 |
一个工具定义的JSON示例:
{
"name": "read_file",
"description": "读取指定文件的内容",
"parameters": {
"filePath": "文件的绝对路径"
}
}你可以把MCP理解为工具的“标准化协议”。它的出现,就是为了解决工具“各自为政”的问题,让不同的工具能够即插即用。
没有MCP的时代(各自为政):
┌─────────┐ 专有协议A
│ Cursor │ ←────────────→ GitHub API
│ │ 专有协议B
│ │ ←────────────→ 数据库
│ │ 专有协议C
│ │ ←────────────→ Figma
└─────────┘
有了MCP之后(统一标准):
┌─────────┐ MCP协议 ┌─────────────┐
│ Cursor │ ←───────→ │ GitHub MCP │
│ │ ←───────→ │ DB MCP │
│ │ ←───────→ │ Figma MCP │
│ │ ←───────→ │ 你自己写的 │
└─────────┘ └─────────────┘几个相关概念:
| 概念 | 说明 |
|---|---|
| MCP Server | 提供工具服务的进程。比如GitHub MCP Server就提供了管理PR、仓库等工具。 |
| MCP Client | 连接和使用MCP Server的Agent宿主,比如WorkBuddy。 |
| 配置文件 | 通常是 `~/.workbuddy/mcp.json`,用来定义你的Agent要连接哪些MCP Server。 |
简单来说,MCP就像USB-C接口——制定一个统一标准,所有设备都能即插即用。
技能可以看作是预封装的领域知识和工作流。它的目的,是让一个通用Agent在特定领域瞬间变成专家。
工具(Tool)提供的是原子操作,比如读文件、搜索。
技能(Skill)提供的是领域专家能力:“遇到PDF解析任务,我知道该按什么步骤、用什么工具来处理。”
一个Skill通常包含:
┌─────────────────────────────────────────┐
│ Skill = 知识 + 工作流 │
│ │
│ ???? SKILL.md(知识文件) │
│ • 这个领域的最佳实践是什么 │
│ • 处理这类任务该用什么工具、什么顺序 │
│ • 有哪些边界情况和注意事项 │
│ │
│ ????️ scripts/(可选的脚本) │
│ • 领域专用的处理脚本 │
│ │
│ ???? references/(可选的参考资料) │
│ • API文档、行业规范等 │
└─────────────────────────────────────────┘LLM是大脑,只能说话,不能做事。
Token是燃料,LLM处理文本的最小单位,Context Window(上下文窗口)有限,需要精打细算。
Context是视野,LLM能“看到”的所有信息的总和,是它产生输出的唯一来源。
Prompt是指令,告诉LLM该做什么、怎么做、遵守什么规则。
Tool是手脚,给Agent提供原子操作能力,比如读文件、执行命令、联网搜索。
MCP是标准接口,让不同的Tool能即插即用,就像USB-C一样方便。
Agent是自主循环的大脑+手脚,能接收任务 → 思考 → 选工具 → 执行 → 观察结果 → 再思考,直到任务完成。
Skill是领域专家的装备包,它不直接调用Tool,而是以自然语言知识文件的形式注入Context,指导Agent在特定领域正确、高效地使用Tool。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。