天玑9500首发解析:不止性能升级 体验和AI表现提升更猛
2025年9月22日,联发科举行了新一代天玑旗舰SoC发布会,正式发布了天玑9500。关注数码半导体的朋友,应该发现了天玑9500发布会的与众不同之
2025年9月22日,联发科举行了新一代天玑旗舰SoC发布会,正式发布了天玑9500。

关注数码半导体的朋友,应该发现了天玑9500发布会的与众不同之处:联发科不止着墨于天玑9500的性能提升,更在体验宣传上下足了猛料,强调能效和AI,特别是能效贯穿了天玑9500的各个模块。
相较于安卓平台的竞争对手们,包括以前的联发科天玑系列,本次联发科天玑9500给人的感觉反而有点苹果A系列那种自成一脉的味道。
所以,天玑9500到底是什么样的呢?恰好现在,我们的面前就有一台真正的天玑9500工程机,大家可以跟着我们一起了解这颗芯片。
CPU:提升不小 但重点是功耗
天玑9500采用目前行业最先进的台积电第三代3nm制程工艺,并继续沿用了标志性的“全大核”设计。
具体来看,天玑9500的CPU包含一颗超大核C1-Ultra@4.21GHz,三颗超大核C1-Premium@3.5GHz,以及四颗大核C1-Pro@2.7GHz。
这里有两点值得关注,第一是架构,天玑9500全线采用Arm在9月初刚发布的基于Arm v9.3-A指令集的新内核,用C1系列CPU代替了旧的Cortex-X系列,性能、能效都有显著提升,其中超大核C1-Ultra比上一代超大核Cortex-X925单线程性能提升25%;第二则是频率,天玑9500的C1-Ultra主频高达4.21GHz,较上代Cortex-X925的3.62 GHz提升约为16%。
在缓存设计上,天玑9500的堆料也颇为良心,虽然联发科没有给出L1缓存的具体数据,但声称相较上一代提升100%;L2缓存与上代持平,超大核C1-Ultra配备2MB L2,三颗超大核C1-Premium各配备1MB L2,四颗大核C1-Pro各配备512KB L2;L3缓存则提升33%,从上一代的12MB,提升至16MB;此外,天玑9500还有10MB的系统缓存。

对于高性能CPU来说,内存延迟是最主要的性能瓶颈,联发科对于更大缓存的投资让L2/L3能缓存更多“热点数据”,减少访问DRAM的次数,有效降低内存延迟,并且对于大规模并行任务和AI性能提升也颇为明显。
事实上,联发科天玑9系一直以来都在缓存设计上颇为“大方”,天玑9500更是继续扩大这种设计的优势,通过瞄准瓶颈去解决问题,起到事半功倍的效果。
基于这些设计变化,天玑9500的单核性能提升约32%,多核性能提升约17%,但比起性能更重要的是功耗,天玑9500达到天玑9400多核性能峰值所需要的功耗,降低了约37%。在日常的高频使用场景中,王者荣耀+语音通话功耗下降30%,4K 120帧视频录制功耗下降22%,视频通话功耗下降12%,短视频功耗下降13%。
其实相比上一代的台积电第二代3nm制程工艺,第三代3nm制程工艺在性能、功耗和密度上的提升仅有5%左右,这一点从晶体管数量上也能看得出来,相比上一代的290亿晶体管,这一代天玑9500的300亿+晶体管规模提升并不大,但无论是性能还是能效,都交出了满意的答卷,这从侧面展现出了天玑9500的架构和设计优势。
天玑9500还着重优化了使用体验,旨在手机操控界面上重现物理世界的感知直觉,比如加快APP启动速度、提高触控丝滑感、稳定算力实现实时响应等。
此外,天玑9500还新增了4通道UFS 4.1的支持,大模型导入速度提升40%,配合Arm v9.3-A的 SVE2、SME2等ISA扩展,同时解决端侧AI“吃不到数据”和“算不快”的瓶颈,在相同功耗下能处理更多Token/s,为端侧AI的应用打下了一个坚实的硬件基础。

而且不得不提的是,目前采用了Arm v9.3-A指令集的天玑9500相较竞争对手们的Arm v8已经有了非常大虚拟化、指令集可扩展性、安全子系统等方面的优势,具有长期的软件和性能收益。
GPU:光追性能飞跃 重新定义旗舰画质
相信大家都听过当下智能手机性能已经溢出的言论,确实诸如原神、崩铁和鸣潮之类的游戏,在搭载上代旗舰处理器的机型上,都差不多能满帧运行了,所以乍听起来这种说法没问题,但仔细考究的话就会发现,原神已经发布5年,崩铁也已经发布2年,游戏画质并非停滞不前,未来的大型游戏性能需求只会更高。
另一方面,老游戏本身的画质和性能需求也会不断提高,比如崩铁就在周年庆针对高性能机型更新了极高画质,渲染分辨率差不多从1680x756提升到了2160x972,看起来差别不大,但理论上的性能需求大约提高了65%,所以对于游戏玩家来说,性能需求永远没有上限。
天玑9500采用最新的Mali G1-Ultra GPU,包含12颗核心和下一代Arm光线追踪单元RTUv2,和上一代的Immortalis-G925相比,光线追踪性能提高100%,峰值性能提高33%,达到G925峰值性能所需要的功耗,降低了约30%。
同时,Mali G1-Ultra GPU支持虚幻引擎5.5 Nanite、虚幻引擎5.6 Megalights,能实现千万量级的三角面渲染和更好的多光源稳定输出,跨平台的Vulkan 1.4则面向开发者,能实现5%的游戏性能提升。
此外,天玑9500还引入了多线程降载能力和天玑调度引擎2.0,通过多线程合理分配渲染任务,降低主线程负载,充分发挥多核优势,同时合理分配前后台资源,让前台程序得到最佳性能的同时,综合功耗也得以降低。
我们以两款游戏为例,首先说明,由于现场提供的是散热未做优化的工程机,咱们重点看性能和功耗表现,至于散热和1%low帧就留待国产厂商的量产机上市,我们再做测试。
首先是高负载的972P极高画质崩坏·星穹铁道,天玑9500在15分钟的黄金时刻-钟表小子广场环形跑测试中,平均帧率为57.1帧。
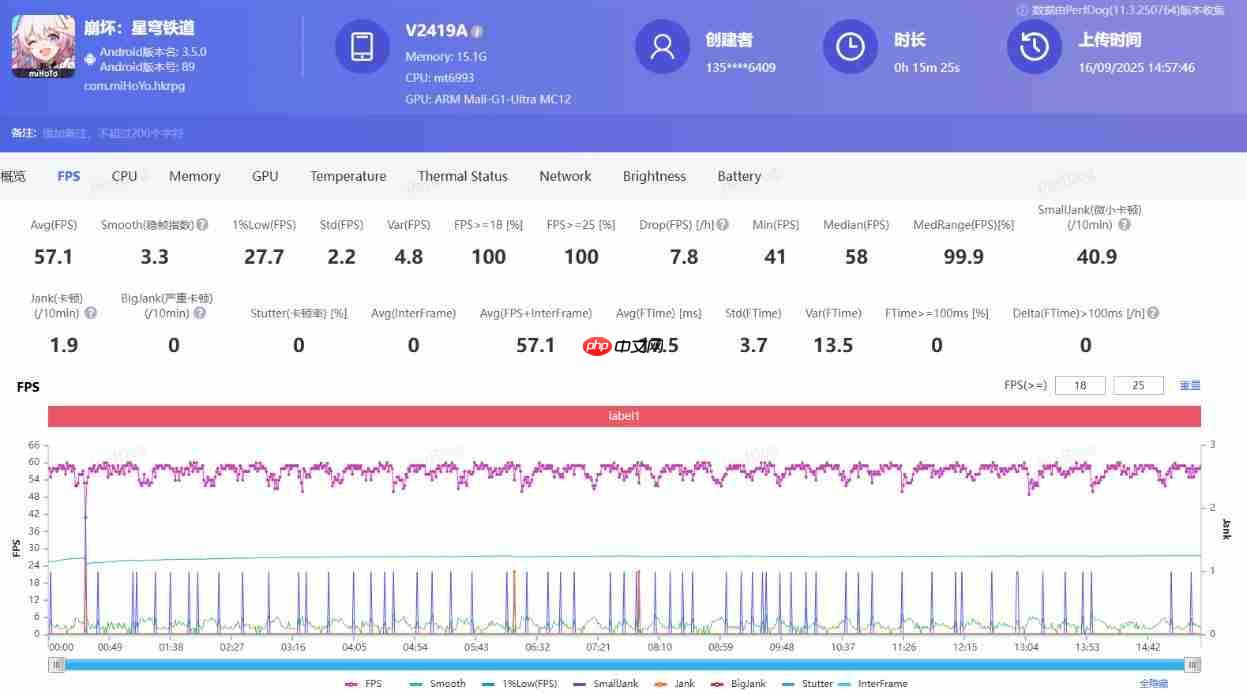
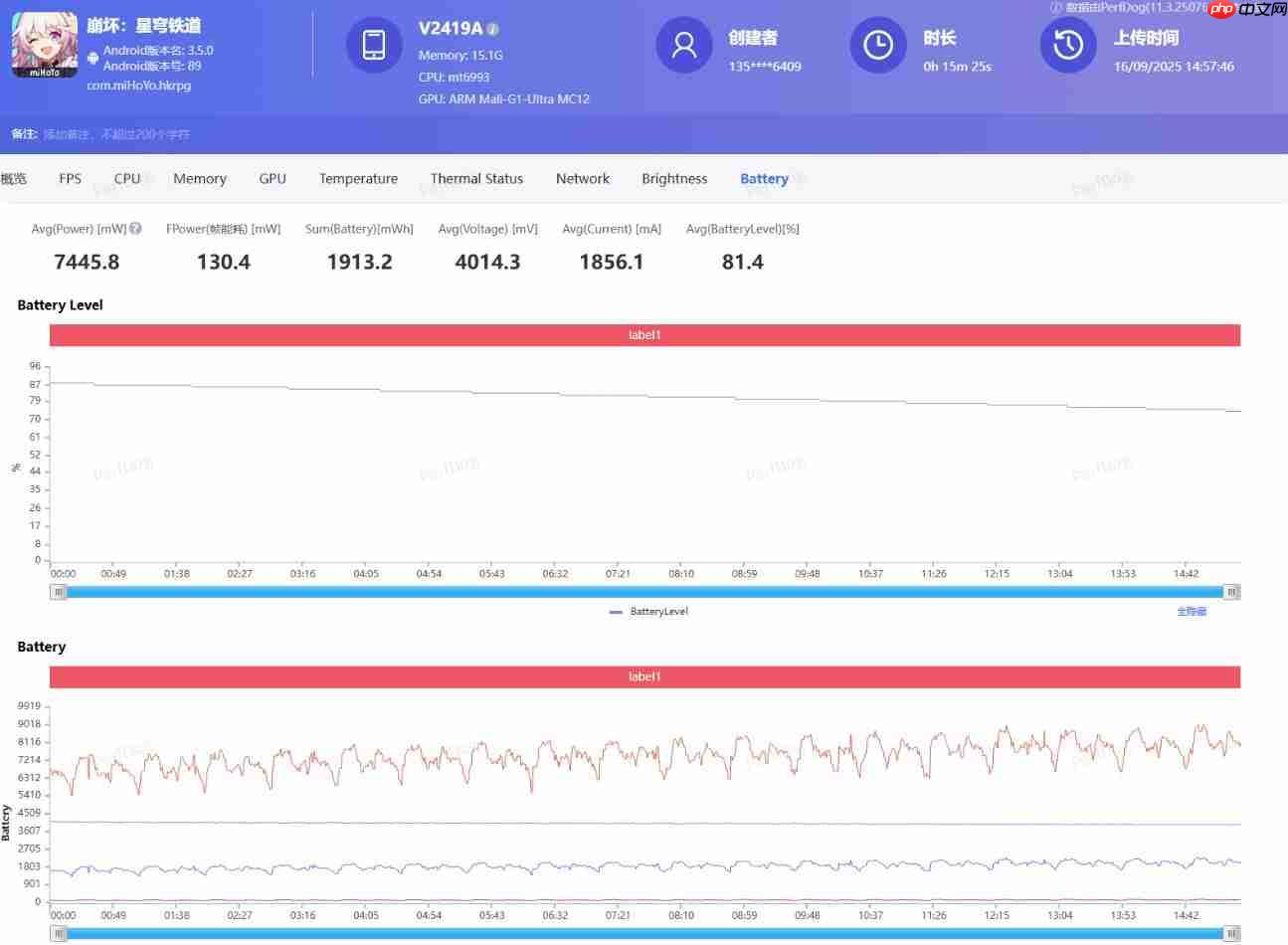
功耗方面,天玑9500约7.4W。
作为对比,天玑9400+在15分钟的黄金时刻-钟表小子广场环形跑测试中,平均帧率55.1帧,功耗约9W。
其次是中低负载的王者荣耀,极致画质+120帧,天玑9500在14分半的一局完整5v5王者峡谷对战中,平均帧率为119.9帧,全程体验非常丝滑流畅。
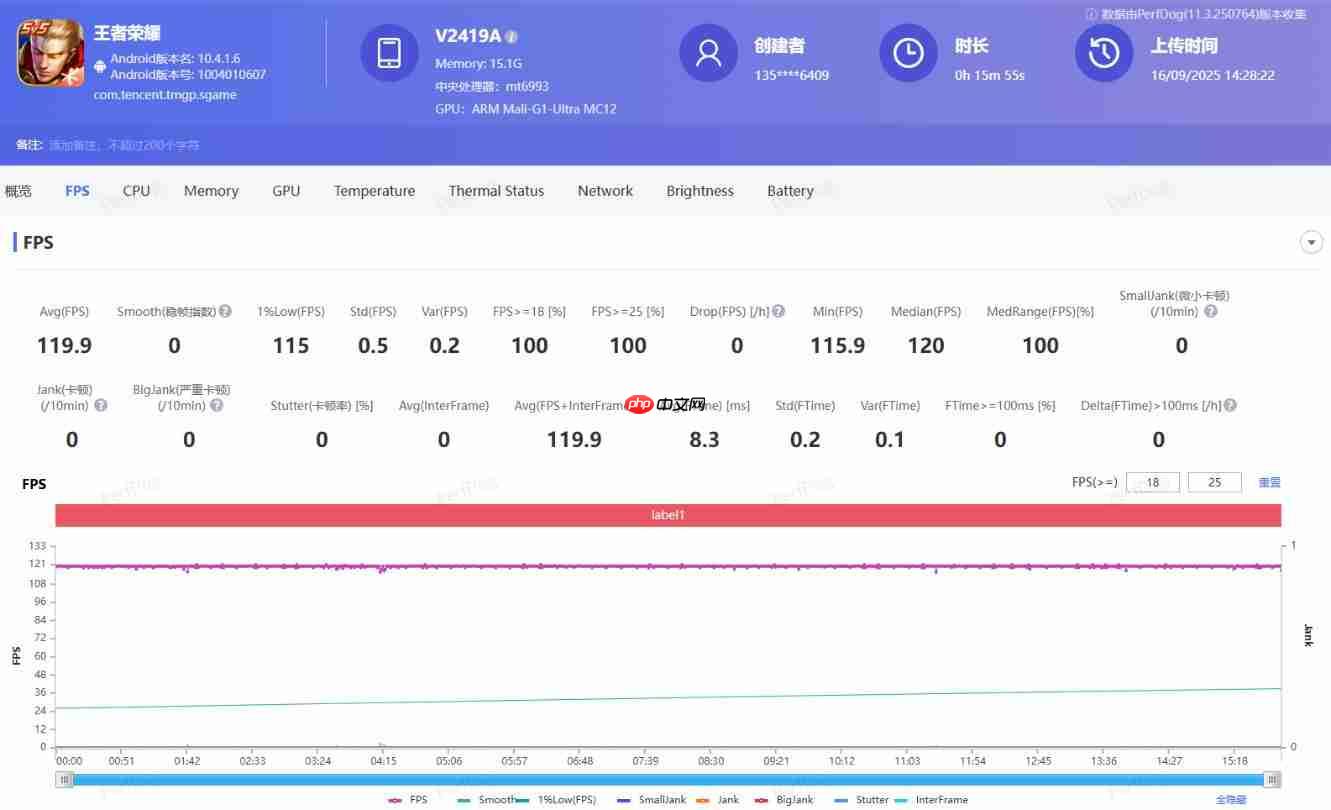
功耗方面,天玑9500则是2496mW,也就是大概2.5W左右。
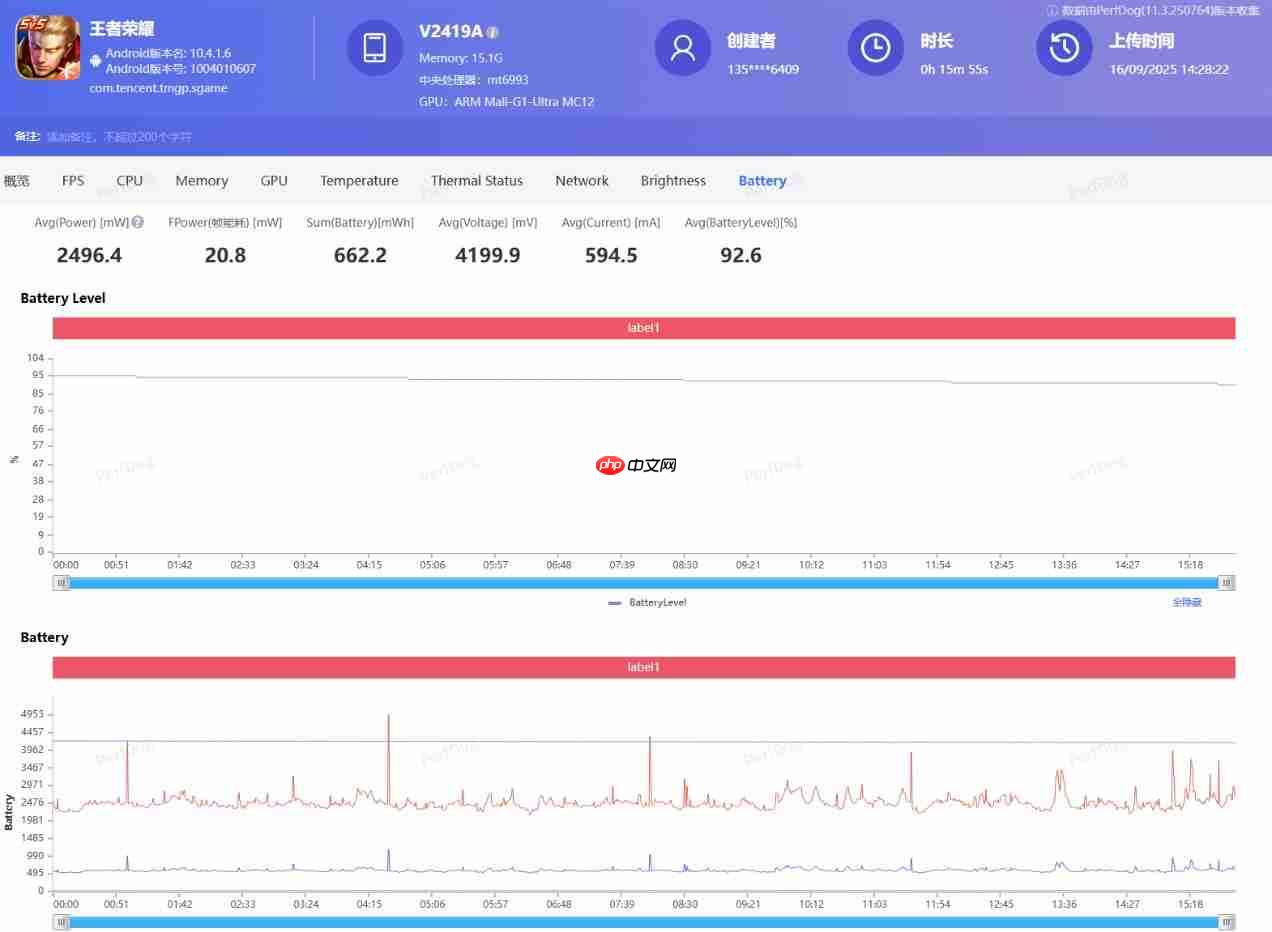
同样作为对比,天玑9400+在一局完整5v5王者峡谷对战中,平均帧率为120.5帧,功耗约3.7W。
从游戏实测的对比上可以看出来,天玑9500在高负载情况下,帧率和功耗对比天玑9400+都有明显提升,中低负载情况下,稳定性更高,功耗也有优化,而且要和大家再次强调,这是工程机的表现,理论上的优化空间还很大,量产机的表现肯定会更好。
可以说,从我们的测试表现来看,天玑9500已经有潜质成为一代‘游戏神U’了。而这背后,也离不开联发科在架构上的技术演进。
天玑9500首先搭载了GPU Dynamic Cache技术,允许GPU在运行时根据不同工作负载,用系统缓存和内存储存,灵活调整资源分配方式,从而提高利用率,让图形运算更高效并降低带宽功耗。据联发科官方人员称,这个技术在《绝区零》能节省600MB/s带宽,实时功耗下降60mA。
同时这一代天玑9500的光线追踪性能提升非常大,光追单元性能直接翻倍,除了RTUv2带来的提升以外,也得益于联发科对于光线追踪这一技术的长远规划,联发科从天玑9200开始引入光线追踪,当时在暗区突围中只能实现30帧的光追游戏体验,然后在产品迭代中逐步推进到60、90和现在的120帧,让光追真正的成为了游戏体验的一部分。
不可否认的是,光线追踪的普及度现在依旧很低,我们能在市面上找到的支持光线追踪的游戏很少,但是如果想在手机上实现3A级的游戏体验,光线追踪带来的画面提升一定是必不可少的。
AI:不只追求性能 更加看重隐私
随着DeepSeek的爆火,生成式AI在手机上的应用越来越多,但这些AI应用的大多数服务都是以对话的形式呈现,使用时基本上都需要上传个人数据,而且可能排队或者付费。
究其根本原因,就是现在的AI应用基本都依赖云端服务,没有办法本地运行,更能没有办法本地训练。
在手机上跑大模型,问题很多:手机的算力有限,模型一大就跑得慢还容易降频;模型常驻和持续运算会发热、耗电,影响续航和体验;同时大模型占用大量内存,DRAM的容量和带宽常常不够,导致读写权重或激活变慢;存储的读写延迟和带宽也会拖慢模型加载与数据交换。
总之是算力、能耗/散热、内存与存储 I/O 这几项很难平衡协同,所以移动端侧AI的进展十分缓慢。
为了解决这些问题,联发科创新式的为天玑9500配备了双NPU 架构,其中一个是超性能NPU 990,峰值性能提升111%,,达到上代NPU 890峰值性能所需要的功耗,降低约56%;另外一个则是存算一体的超能效NPU,支持Always-on。

超性能NPU 990采用Transformer专用固化电路设计,从硬件层面提高计算密度并减少控制开销;在软件栈上原生支持BitNet 1.58-bit推理框架技术,显著压缩模型体积与内存带宽需求,性能提高2倍,内存节省60%;集成内存压缩技术,减少对DRAM/UFS的读写频次与带宽峰值,从而降低带宽相关的功耗与发热;此外,LoRA端侧部署,以极小的适配矩阵实现个性化或增量更新,避免全模型微调带来的体积与计算开销。

通过这套方案,联发科宣称超性能NPU 990不仅支持端侧大模型的训练和4K文生图等应用,还将3B大模型的文生文生成速度提升100%,那在我们的实际体验中,一张4K分辨率的文生图,在12S内便可完成。

还有比如现在常见的通话录音摘要/会议摘要,文档内容摘要等功能,天玑9500的超性能NPU 990都可以在不联网的情况下生成。

并且超性能NPU 990在处理这种文字内容时,不仅速度可以媲美云端,而且长文本处理长度从32K升到了128K,相当于2.5小时和10小时的录音量。

联发科展示的其他方面AI功能还包括AI风格化的个人形象、AI自动翻译等等。
其实这些功能大家应该都或多或少的使用过。当然,如果和云端AI做比较,天玑9500的超性能NPU 990在这些功能上的表现并没有更出色的地方,甚至由于云端大模型对端侧大模型参数量级不同,部分体验可能并不如云端大模型,不过随着端侧能力越来越强,到天玑 9500 的端侧 AI ,总归是从能用到好用的状态了。
但端侧和云端并不是强制的2选1,而是可以互补共存的,端侧大模型的创造力具备和云端大模型的可比性,那在使用时无需排队或付费,也不用担心任何隐私问题,就是端侧大模型最大的优势。
而且只有端侧才能够实现全链路的AI系统整合,云端的AI只能去实现某些功能。
同时,超性能NPU 990对于端侧大模型训练的支持,可能会延伸出更加多样化和个性化的手机功能。据联发科透露,首批搭载天玑9500的部分品牌机型将支持端侧美颜大模型的训练,通过让大模型学习用户的长相、审美和喜好,生成专属的美颜参数,并且通过使用和学习,不停的自我进化和自我迭代。
说实话,这个功能其实是整个天玑9500最让笔者震惊的地方,就目前来看它只是一个美颜,但这个功能有无限的可能性,可训练的大模型上限实在太高了,比如同样是拍照,把美颜换成街拍、风景又是一个新的功能。如果大胆一点,给手机的智能助理接入这种可训练的大模型呢?如果再大胆一点,既然是完全本地运行的大模型,不会泄露个人隐私,那能否让它读取我在手机上的所有个人信息,从而替我处理某些个人事务呢?
可以说天玑9500真的让笔者有一种好用的端侧AI真正到来的感觉。
不过超性能NPU 990虽然很强,能效也有提升,但日常场景大概3-4W的功耗预算还是有点高,所以联发科又设计了存算一体的超能效NPU。

NPU运算时需要反复读取数据,因此内存读取的功耗巨大,存算一体的超能效NPU将数据存储与计算单元合并,最大化片上命中率,降低系统级延迟和带宽峰值,能效大幅提升,也因此,超能效NPU可以实现24小时待命,直接处理小规模的AI任务,比如识屏,意图搜索,互动协作等等。
ISP:坚持追赶 目标超越苹果
天玑9500搭载全新的ISP Imagiq 1190,重点升级了人像渲染引擎和RAW域处理引擎,在算力方面有明显提升,首发4K 60帧电影级人像渲染引擎,可以进行光斑、皮肤细节和调色的多重处理,支持双轨防抖算法视频录制4K 120Hz。
天玑9500模仿专业相机,在录制视频时,将超能效NPU作为专属的追焦核心,通过和ISP组合,实现物件追踪和实时对焦,追踪延迟和对焦延迟降低至33ms,大幅领先竞争对手。
在过去几年,安卓平台的拍照能力已经普遍追赶甚至超越了苹果,但受限于ISP算力,视频能力一直较iPhone有比较大的差距。也正是因此,这一代的Imagiq 1190的主要提升就是视频能力,对此,联发科在相关沟通中表达了对iPhone视频能力的尊敬,也明确表达了天玑9500虽然仍在追赶,但也力求在某些地方媲美甚至超越苹果。
除了拍照,天玑9500还利用Imagiq 1190实现了一些有趣的技术,比如MiraVision自适应显示效果,可以在OLED屏幕上实现像素级的对比度和色彩饱和度自动适应,比如通过对比度和饱和度的调整,实现同样1nit极暗情况下的更清晰视觉效果。

此外,Imagiq 1190优化了功耗,相比上一代功耗降低了约10%。
总结:着重体验 押宝AI 天玑9500或走出一条不一样的安卓路?
本次天玑9500的体验着实仓促,所以很多内容都没能给大家展示到,包括真实的光追开关效果对比,端侧AI回答质量的对比,人像视频和自动追焦的效果等等等等,这些遗憾可能只能等天玑9500量产机型的发布了。
不过就目前的表现来看,天玑9500给人的感觉就是闲庭信步。
得益于新架构、新指令集和新设计,天玑9500在性能和功耗大幅提升的同时,依然留出了很大的余力去加强自己的AI能力,特别是双NPU的领先设计,在目前这个AI时代的重要性不言而喻。
虽然今年下半年的芯片大战才刚刚揭幕,最终胜负尚未可知,但天玑9500已经在传统的性能战场之外,开辟了一条新的赛道,从某种角度上来说,已经立于了不败之地,甚至于天玑9500可能会重塑智能手机行业对于AI手机的定位。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。
相关文章
更多>>









热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 流浪武士手游排行榜-流浪武士手游下载-流浪武士游戏版本大全
- 光通传奇游戏排行-光通传奇所有版本-光通传奇游戏合集
- 轩辕剑3游戏版本排行榜-轩辕剑3游戏合集-2023轩辕剑3游戏版本推荐
- 熔芯聚变手游排行-熔芯聚变免费版/单机版/破解版-熔芯聚变版本大全
- 2023荆棘王座手游排行榜-荆棘王座手游2023排行榜前十名下载
- 天空时代排行榜下载大全-2023最好玩的天空时代前十名推荐
- 冰雪斩龙排行榜下载大全-2023最好玩的冰雪斩龙前十名推荐
- 玉剑仙诀手游2023排行榜前十名下载_好玩的玉剑仙诀手游大全
- 茅山道尊游戏排行-茅山道尊所有版本-茅山道尊游戏合集
- 类似少前谲境的手游排行榜下载-有哪些好玩的类似少前谲境的手机游戏排行榜
- 暗黑血源排行榜下载大全-2023最好玩的暗黑血源前十名推荐
- 火龙传奇手游2023排行榜前十名下载_好玩的火龙传奇手游大全





