太震撼了!梁文锋带领DeepSeek团队发表注意力新机制重磅论文,网友:这才是真正的OpenAI
就在马斯克发布了grok3,而sam altman还在犹豫是否要开源时,梁文锋作为共同作者,与deepseek研
就在马斯克发布了grok3,而sam altman还在犹豫是否要开源时,梁文锋作为共同作者,与deepseek研究团队一起发布了重磅研究论文,deepseek推出了最新的研究成果——原生稀疏注意力(native sparse attention, nsa)!这一技术有望显著提升下一代大语言模型处理长文本的能力,同时还能兼顾效率,可谓是llm领域的又一里程碑式进展!

简单来说,论文的核心贡献如下:
不多废话,我们一起来看看这篇论文:
首先了解一下论文的背景。近年来,长文本建模在AI领域的重要性日益凸显。无论是深度推理、代码库生成,还是多轮对话,都离不开模型对长序列信息的有效处理能力。像OpenAI的o-series模型、DeepSeek-R1以及Google Gemini 1.5 Pro等,都展示了处理超长文本的强大潜力。
然而,传统Attention机制的计算复杂度随着序列长度的增加而呈平方级增长,这成为了制约LLM发展的关键瓶颈。计算成本高昂,延迟成为问题,如何在保证模型性能的同时,提升长文本处理的效率,成为了亟待解决的难题。
稀疏注意力应运而生,被认为是提升效率,同时维持模型能力的有希望的方向。DeepSeek的NSA技术正是在这个方向上迈出了重要一步!
DeepSeek NSA:原生稀疏注意力,训推一体化,硬件友好。DeepSeek提出的NSA(Native Sparse Attention,原生稀疏注意力)机制,巧妙地将算法创新与硬件优化相结合,旨在实现高效的长文本建模。
NSA的核心亮点可以概括为以下两点:
动态分层稀疏策略:NSA采用了一种动态分层的稀疏策略,结合了粗粒度的Token压缩和细粒度的Token选择。这种策略既能保证模型对全局上下文的感知,又能兼顾局部信息的精确性。
两大关键创新:
- 算术强度平衡的算法设计与硬件优化:NSA通过精巧的算法设计,并针对现代硬件进行了实现优化,显著提升了计算速度。
- 端到端可训练:NSA支持端到端训练,这意味着它不仅在推理阶段高效,还能减少预训练的计算量,同时不牺牲模型性能!
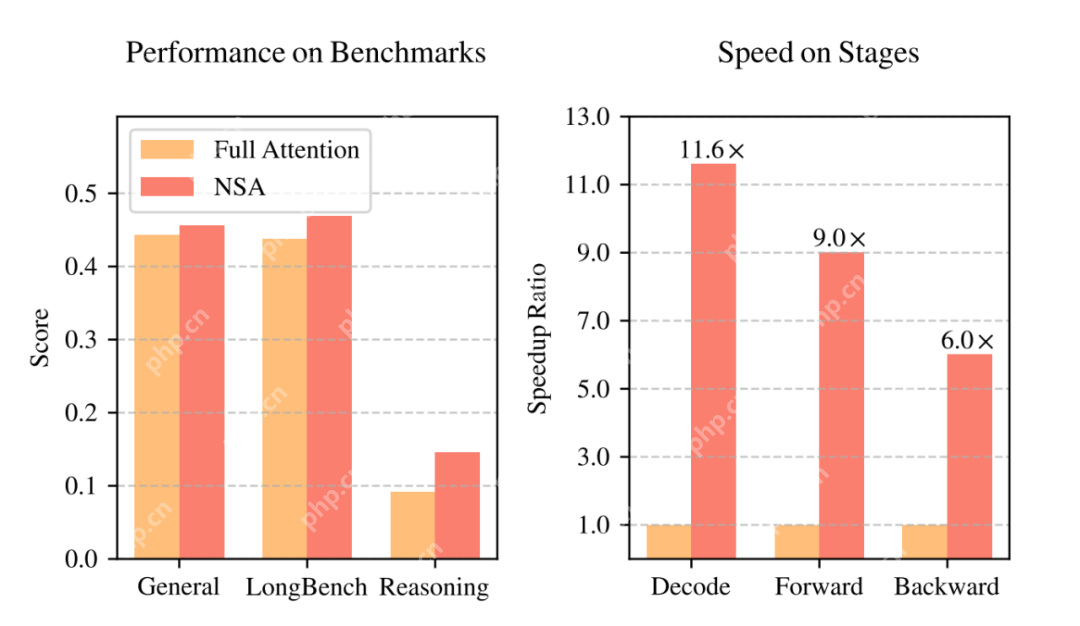
? 实验效果惊艳:性能不降反升,速度大幅提升!实验结果令人振奋!如图1所示,在通用基准测试、长文本任务和指令推理方面,使用NSA预训练的模型性能不仅没有下降,反而超越了Full Attention模型!
更重要的是,在处理64k长度的序列时,NSA在解码、前向传播和反向传播等各个阶段都实现了显著的速度提升,最高可达11.6倍!这充分证明了NSA在模型生命周期各个阶段的效率优势。
? 现有稀疏注意力方法的局限性。论文也深入分析了现有稀疏注意力方法的局限性,主要体现在两个方面:
推理效率的“假象”:很多方法虽然在理论上实现了稀疏计算,但在实际推理延迟方面提升有限。这主要是因为:
- 阶段限制的稀疏性:例如,有些方法只在自回归解码时应用稀疏性,但在预填充阶段仍然需要大量计算。
- 与先进Attention架构的不兼容性:一些稀疏注意力方法难以适配像MQA和GQA这样的现代高效解码架构,导致内存访问瓶颈依然存在。
可训练稀疏性的“神话”:许多方法主要关注推理阶段的稀疏性,而忽略了训练阶段。这导致:
- 性能退化:后验应用稀疏性可能导致模型偏离预训练的优化轨迹。
- 训练效率需求:长序列训练对于提升模型能力至关重要,但现有方法在训练效率方面存在不足。
- 不可训练的组件:一些方法引入了不可微的离散操作,阻碍了梯度传播,限制了模型学习最佳稀疏模式的能力。
- 反向传播效率低下:一些理论上可训练的方法,在实际训练中效率低下,例如Token粒度的选择策略可能导致非连续的内存访问,影响硬件利用率。
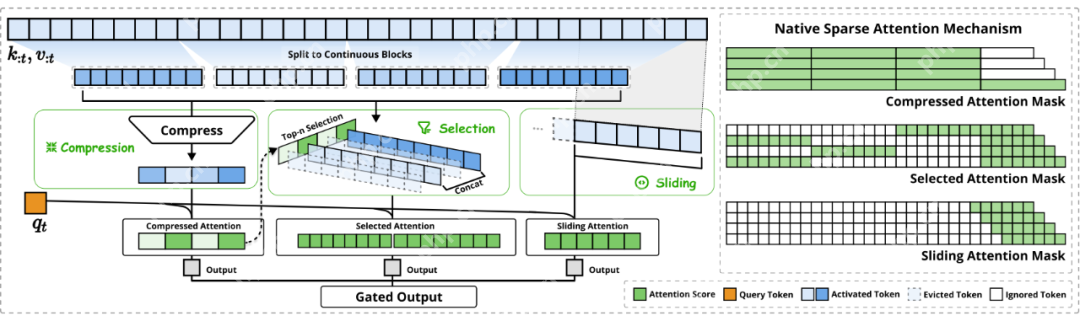
? NSA的核心组件:分层稀疏,逐层优化。为了克服上述局限性,NSA架构采用了分层Token建模,并通过三个并行的注意力分支处理输入序列:
- 压缩注意力(Compressed Attention):处理粗粒度的模式,通过压缩Token块来捕获全局信息。
- 选择注意力(Selected Attention):处理重要的Token块,选择性地保留细粒度的信息。
- 滑动窗口注意力(Sliding Window Attention):处理局部上下文信息。
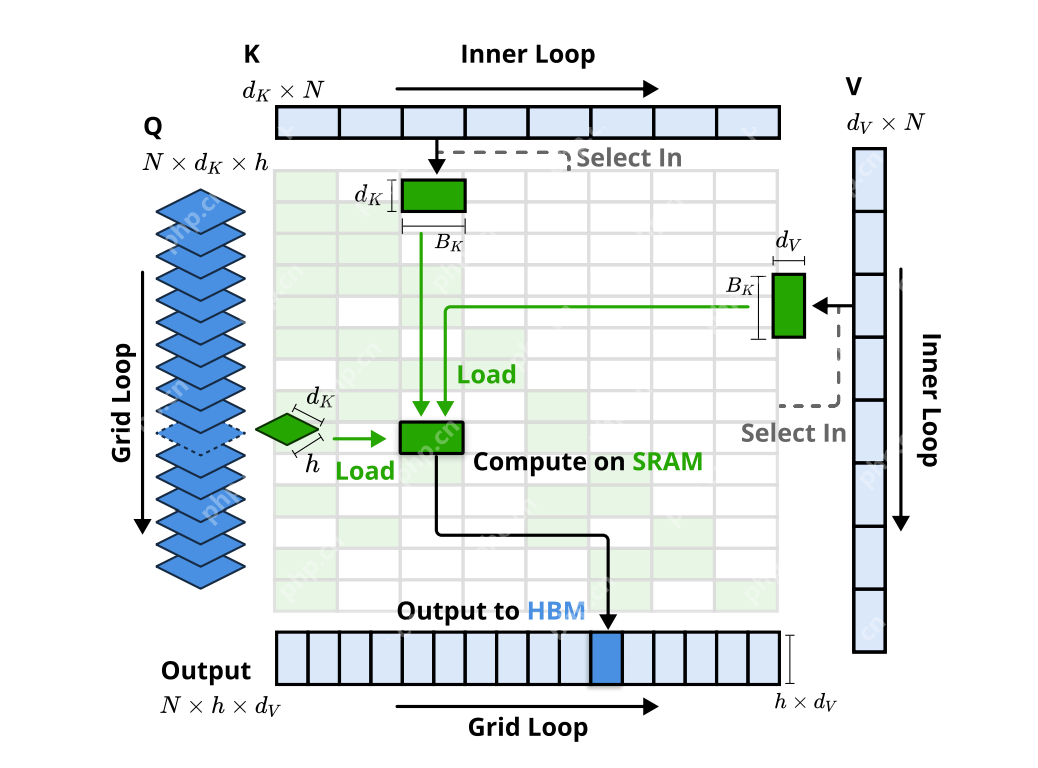
这三个分支的输出通过一个门控机制进行聚合。为了最大化效率,NSA还专门设计了硬件优化的Kernel。
写在最后:DeepSeek的NSA技术为长文本建模带来了新的突破。它不仅在性能上超越了传统的Full Attention模型,更在效率方面实现了显著的提升,尤其是在长序列场景下。NSA的硬件友好设计和训推一体化特性,使其在实际应用中更具优势,有望加速下一代LLM在长文本处理领域的应用落地。
这项研究无疑为稀疏注意力领域带来了新的思路和方向。未来,我们期待看到更多基于NSA技术的创新应用,共同推动AI技术的进步!
最后不得不再次强调,梁文锋不仅是deepseek的CEO,很明显他还在研究的最前沿参与研究,这是令我最震撼的,他不仅有管理能力,而且还真正懂AI,deepseek前途无量。
各路网友都在喊,这才是真正的OpenAI,?
论文地址:
https://www.php.cn/link/c9eca6cff4f25c6b73be4bfbd546b1d3
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。

相关文章
更多>>












热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 多种热门耐玩的荣耀传世破解版游戏下载排行榜-荣耀传世破解版下载大全
- 协同小组手游排行-协同小组免费版/单机版/破解版-协同小组版本大全
- 多种热门耐玩的绝命修仙破解版游戏下载排行榜-绝命修仙破解版下载大全
- 最强修真手游2023排行榜前十名下载_好玩的最强修真手游大全
- 类似一剑九霄的游戏排行榜_有哪些类似一剑九霄的游戏
- 业力轮回手游2023排行榜前十名下载_好玩的业力轮回手游大全
- 万道仙君题材手游排行榜下载-有哪些好玩的万道仙君题材手机游戏推荐
- 至尊皓月手游2023排行榜前十名下载_好玩的至尊皓月手游大全
- 鸣剑九天排行榜下载大全-2023最好玩的鸣剑九天前十名推荐
- 九天仙缘题材手游排行榜下载-有哪些好玩的九天仙缘题材手机游戏推荐
- 经典传世排行榜下载大全-2023最好玩的经典传世前十名推荐
- 天雷滚滚最新排行榜-天雷滚滚手游免费版下载-天雷滚滚免费破解版下载





