大模型与AI底层技术揭秘(27)食神挑战烤肥肠
小h最近因为沉迷于学习,体重减轻了不少,小伙伴们决定带他去享受美食。他们来到一家专门烤羊腿
小h最近因为沉迷于学习,体重减轻了不少,小伙伴们决定带他去享受美食。
他们来到一家专门烤羊腿和肥肠的餐馆,虽然人很多,但老板娘热情地招呼他们,说里面有包间,刚好能容纳6个人。小H和朋友们进入包间就座。尽管包间只是用屏风隔开的,看起来很简单,但比大厅要好。这些小包间看起来都是独立的。
用餐过程中,他们听到外面有人在吵:
“碱水面没有经过冷水处理,所以面里全是碱水味,鱼丸也没有鱼味,但你为了掩饰特意加了咖喱汁,想把它做成咖喱鱼丸,但这么做太简单,有时甚至是天真!原本美味的咖喱鱼丸,被你做得既没有鱼味也没有咖喱味,失败!萝卜没有挑选过,筋太多,失败!猪皮煮得太烂,失败!猪血一夹就散,失败中的失败!最糟糕的是肥肠,里面根本没洗干净,还有一坨……”
 “你以为这里是香港吗?我们北方人吃肥肠就讲究不洗干净,洗干净就没味道了!滚!”老板娘指着来挑衅的人骂道。
“你以为这里是香港吗?我们北方人吃肥肠就讲究不洗干净,洗干净就没味道了!滚!”老板娘指着来挑衅的人骂道。
这时,外面有人因为喝多了,并且听了老板娘的话,开始呕吐(Core Dump)。
 小H和朋友们看着桌上吃了一半的烤肥肠,胃里翻江倒海,然后也有人吐了。趁着混乱,他们离开了餐馆,没有付钱。
小H和朋友们看着桌上吃了一半的烤肥肠,胃里翻江倒海,然后也有人吐了。趁着混乱,他们离开了餐馆,没有付钱。
方老师听完小H的故事,先是笑了一会儿,然后问小H:
上次学的NVidia vCUDA GPU虚拟化,你还记得吗?这个方案有什么缺陷?
小H想了想,总结道:vCUDA是替换虚拟机上的CUDA,让它连接到宿主机上的vCUDA Stub,然后调用宿主机上的GPU进行计算的方案。如果使用其他API库,就无法在虚拟机上使用GPU了。
小H突然想到,如果GPU支持SRIOV技术,将PF虚拟化为多个VF并直接传递给虚拟机,是不是就可以让多个虚拟机共享GPU的计算能力了呢?
实际上,NVidia在GPU领域的竞争对手AMD(收购了ATI的GPU),就采用了基于SRIOV的GPU虚拟化方案。
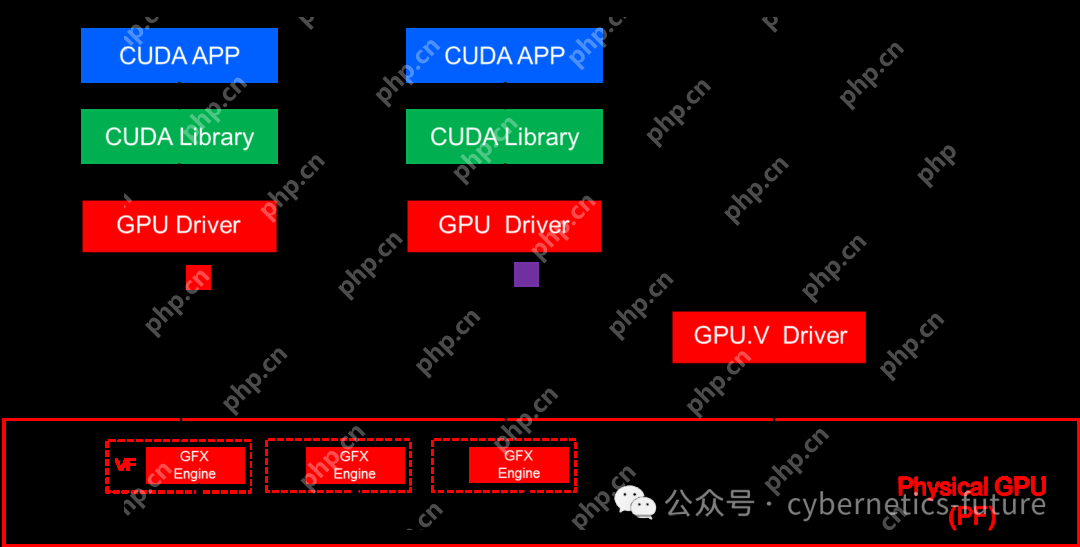 如图所示,AMD的GPU本身是PCI-E SRIOV的PF(物理功能),而每个虚拟化实例是一个VF(虚拟功能),并直接传递给一个VM。
如图所示,AMD的GPU本身是PCI-E SRIOV的PF(物理功能),而每个虚拟化实例是一个VF(虚拟功能),并直接传递给一个VM。
GPU的VF直接传递给VM的方式,与我们在前几期中学习的物理设备直接传递给VM实际上没有实质性差异,GuestOS看到的是经过Hypervisor调用IOMMU后映射的配置空间、Virtual BAR和DMA地址,CPU上的IOMMU和MMU会将地址翻译为物理地址,也就是让虚拟机能够操作真实的硬件。同时,VF产生的MSI中断也可以由vAPIC发送给虚拟机进行处理。
VM能够访问GPU后,就可以使用原生的CUDA应用和GPU驱动来访问VF设备,提交计算任务并在GPU中完成计算。
然而,SRIOV方式实现的GPU虚拟化有一个严重缺陷:只提供对虚拟机可见的多个设备,无法实现内部资源的隔离。也就是说,任何一个VM的CUDA程序越界访问GPU内存,都会导致其他VM的CUDA应用异常终止!
小H想到了昨晚在饭店的经历,虽然表面上自己在独立的包间用餐,但实际上并没有真正实现物理隔离。其他食客的异常操作(Core dump)导致了小H和朋友们的用餐任务异常终止(也有人Core dump了)。
看来,基于SRIOV的GPU虚拟化并不是一个好的方案。
那么,为什么网卡的SRIOV虚拟化在NFV场景中能够得到广泛应用呢?
这是因为,网卡实际上是一个无状态(stateless)的设备。网卡本身不承担计算任务,数据包的收发、关键字段的提取计算和收到的数据包分发到目标队列,实际上都是硬件定义的原子操作,不会被软件程序打断。因此,网卡的SRIOV实现实际上只是将一定数量的收发队列分配给VF。
但是GPU的复杂度远超网卡。它是一个有状态(stateful)的设备。GPU内部有各种计算单元、缓存和RAM控制器,这些部件的状态是由GPU计算指令决定的。实际上,GPU可以被认为是一个高度并行、图灵完备的向量计算机。在这样一个复杂的硬件中,实现硬件级别的虚拟化隔离,其难度甚至超过Intel在x86中引入VT-X系列特性!
因此,即使是在硬件虚拟化技术方面有深厚积累的Intel,在其GPU虚拟化路线上,也没有采用SR-IOV,而是使用了其他方案。
请看下期。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。

相关文章
更多>>









热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 类似风云剑圣的游戏排行榜_有哪些类似风云剑圣的游戏
- 姬神物语手游排行-姬神物语免费版/单机版/破解版-姬神物语版本大全
- 类似勇者神途的游戏排行榜_有哪些类似勇者神途的游戏
- 工匠物语题材手游排行榜下载-有哪些好玩的工匠物语题材手机游戏推荐
- 上古三国排行榜下载大全-2023最好玩的上古三国前十名推荐
- 铁血守卫游戏排行-铁血守卫所有版本-铁血守卫游戏合集
- 最终契约手游2023排行榜前十名下载_好玩的最终契约手游大全
- 铁血战魂系列版本排行-铁血战魂系列游戏有哪些版本-铁血战魂系列游戏破解版
- 可靠快递系列版本排行-可靠快递系列游戏有哪些版本-可靠快递系列游戏破解版
- 类似幻灵天命的游戏排行榜_有哪些类似幻灵天命的游戏
- 鸣剑九天手游排行-鸣剑九天免费版/单机版/破解版-鸣剑九天版本大全
- 黑域生存系列版本排行-黑域生存系列游戏有哪些版本-黑域生存系列游戏破解版





