使用Mixtral-offloading在消费级硬件上运行Mixtral-8x7B
mixtral-8x7b被视为顶尖的开放大型语言模型之一,但其46 7b的参数使其难以在消费级gpu上完全加载
mixtral-8x7b被视为顶尖的开放大型语言模型之一,但其46.7b的参数使其难以在消费级gpu上完全加载,即使量化为4位,24 gb的vram仍不足以容纳该模型。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
作为混合专家(MoE)模型,Mixtral-8x7B由8个专家子网组成,每个子网有60亿个参数。在解码期间,仅有2个专家被激活,其余6个专家可以移动或卸载到其他设备如CPU RAM,从而释放一些GPU VRAM。然而,这种操作在实践中非常复杂。
选择激活哪个专家是在对每个输入令牌和模型的每一层进行推理时决定的。如果暴力地将模型的某些部分移到CPU RAM中,会在CPU和GPU之间造成通信瓶颈。
Mixtral-offloading提出了一种更有效的解决方案,以减少VRAM消耗,同时保持合理的推理速度。本文将解释Mixtral-offloading的工作原理,并展示如何使用这个框架节省内存并保持良好的推理速度。我们还将看到如何在消费者硬件上运行Mixtral-8x7B,并对其推理速度进行基准测试。
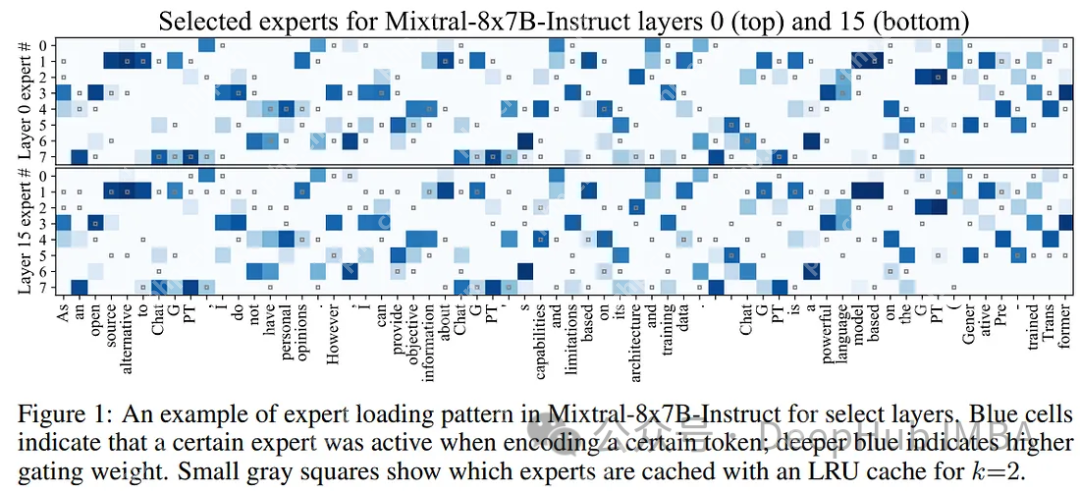
为了利用MoE语言模型中专家的激活模式,Mixtral-offloading的作者建议将活跃的专家保存在GPU内存中,作为未来令牌的“缓存”。这确保了如果再次需要相同的专家时可以快速获得帮助。GPU内存限制了存储专家的数量,并使用了一个简单的LRU(Least Recently Used)缓存,在所有层上统一维护k个最近使用的专家。
尽管LRU缓存策略简单,但它显著加快了Mixtral-8x7B等MoE模型的推理速度。尽管LRU缓存提高了专家的平均加载时间,但很大一部分推理时间仍然需要等待下一个专家加载。专家加载与计算之间缺乏有效的重叠。
在标准(非MoE)模型中,有效的卸载包括在前一层运行时预加载下一层。这种方法对于MoE模型来说是不可行的,因为专家是在计算时选择的。在确定要加载哪些专家之前,系统无法预取下一层。尽管无法可靠地预取,但作者发现可以在处理前一层时猜测下一个专家,如果猜测是正确的,可以加速下一层的推理。
综上所述,LRU缓存和推测卸载可以节省VRAM。
除了Speculative Offloading之外,量化模型是消费者硬件上运行的必不可少的操作。使用bitsandbytes的NF4进行简单的4位量化可以将模型的大小减少到23.5 GB,但如果假设消费级GPU最多有24 GB的VRAM,这仍然不够。
先前的研究表明,在不影响模型性能的情况下,MoE专家可以量化到较低的精度。可以采用混合精度量化,将非专家的参数保持在4位。
在Mixtral-8x7B的467亿个参数中,96.6%(451亿个)用于专家,其余的分配给嵌入、注意力、MoE门和其他次要层,如LayerNorm。
对于量化,可以选择使用Half Quadratic Quantization(HQQ)(Badri & Shaji, 2023),这是一种适应各种比特率的无数据算法。
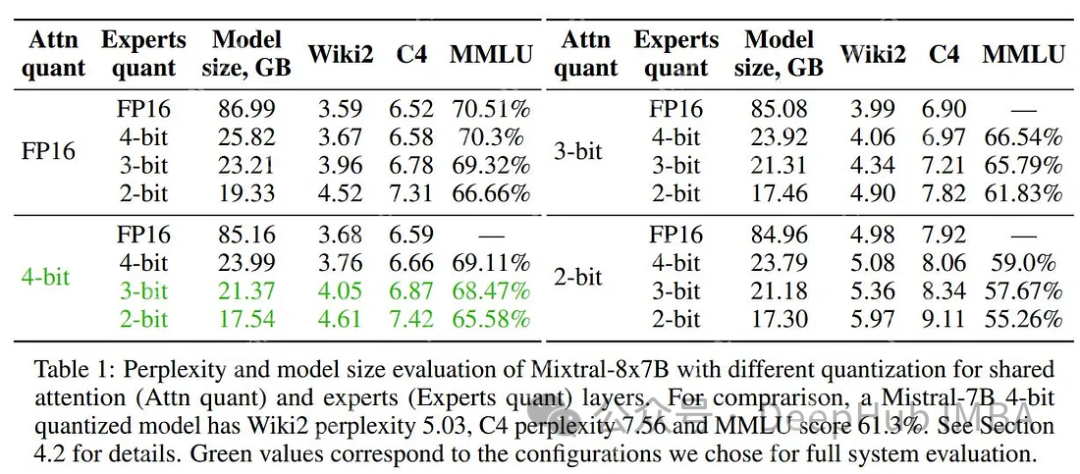
Mixtral-offloading的作者尝试了各种量化配置:FP16(不量化)、HQQ 4位(组大小64,规模组大小256)、HQQ 3位(组大小64,规模组大小128)、HQQ 2位(组大小16,规模组大小128)。
下表所示,将专家量化为3位或2位,同时将注意力层保持在更高的位(16位或4位)得到的结果是非常好的。
在应用量化和Speculative Offloading后,推理速度比使用Accelerate(device_map)实现的Offloading快2到3倍:
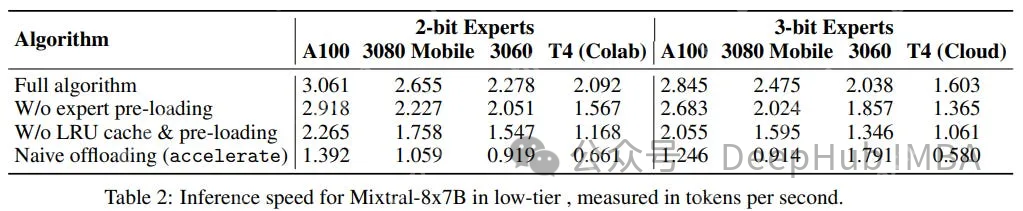
为了验证Mixtral-offloading,我们使用Google Colab的T4 GPU,因为它只有15 GB的VRAM可用。这是一个很好的基线配置来测试生成速度。
首先,我们需要安装所需的包:
git clone https://github.com/dvmazur/mixtral-offloading.git --quietcd mixtral-offloading && pip install -q -r requirements.txt登录后复制
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。

相关文章
更多>>












热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 天道仙尊游戏版本排行榜-天道仙尊游戏合集-2023天道仙尊游戏版本推荐
- 灵汐缘2手游2023排行榜前十名下载_好玩的灵汐缘2手游大全
- 口袋觉醒题材手游排行榜下载-有哪些好玩的口袋觉醒题材手机游戏推荐
- 龙之神途手游排行榜-龙之神途手游下载-龙之神途游戏版本大全
- 梦中的你手游排行榜-梦中的你手游下载-梦中的你游戏版本大全
- 永恒战士排行榜下载大全-2023最好玩的永恒战士前十名推荐
- 炎黄大陆手游排行榜-炎黄大陆手游下载-炎黄大陆游戏版本大全
- 山海夜行手游2023排行榜前十名下载_好玩的山海夜行手游大全
- 类似白蛇问仙的手游排行榜下载-有哪些好玩的类似白蛇问仙的手机游戏排行榜
- 荒岛生存最新排行榜-荒岛生存手游免费版下载-荒岛生存免费破解版下载
- 圣武逍遥手游2023排行榜前十名下载_好玩的圣武逍遥手游大全
- 一念永恒最新排行榜-一念永恒手游免费版下载-一念永恒免费破解版下载





