大模型与AI底层技术揭秘(23)抽象派的小黑子
小h在学习了本专题后,开始思考一个问题:人的大脑相当于什么级别的CPU和GPU呢?小H仔细思考后,
小h在学习了本专题后,开始思考一个问题:
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
人的大脑相当于什么级别的CPU和GPU呢?
小H仔细思考后,发现自己在计算这个问题:
将48331804981分解为两个质数的积
远比计算机CPU慢很多倍。
然而,当他看到这张图时,却能立即进行渲染(脑补)并识别出图中的人:
 这让他觉得自己的大脑似乎能与NVidia H100集群一较高下。
这让他觉得自己的大脑似乎能与NVidia H100集群一较高下。
方老师发现了小H的想法,嘲笑他:你怎么也学小学生的恶趣味呢?
小H尴尬地回到座位,继续研究上期遗留的问题。
在上期,我们留下了另一个问题:在ARM Cortex-A体系架构下,如何让虚拟机的操作系统能够访问到PCI-E设备的配置空间、IO BAR空间和DMA缓冲区?
我们先来看看在Intel体系架构下是如何解决这一问题的。
在Intel的32位(x86)或64位(x64)模式下,PCI-E配置空间实际上是一段位于系统内存区域的地址,访问这段地址应使用普通的基址变址指令,而不需要使用用于系统IO端口访问的input/output指令。
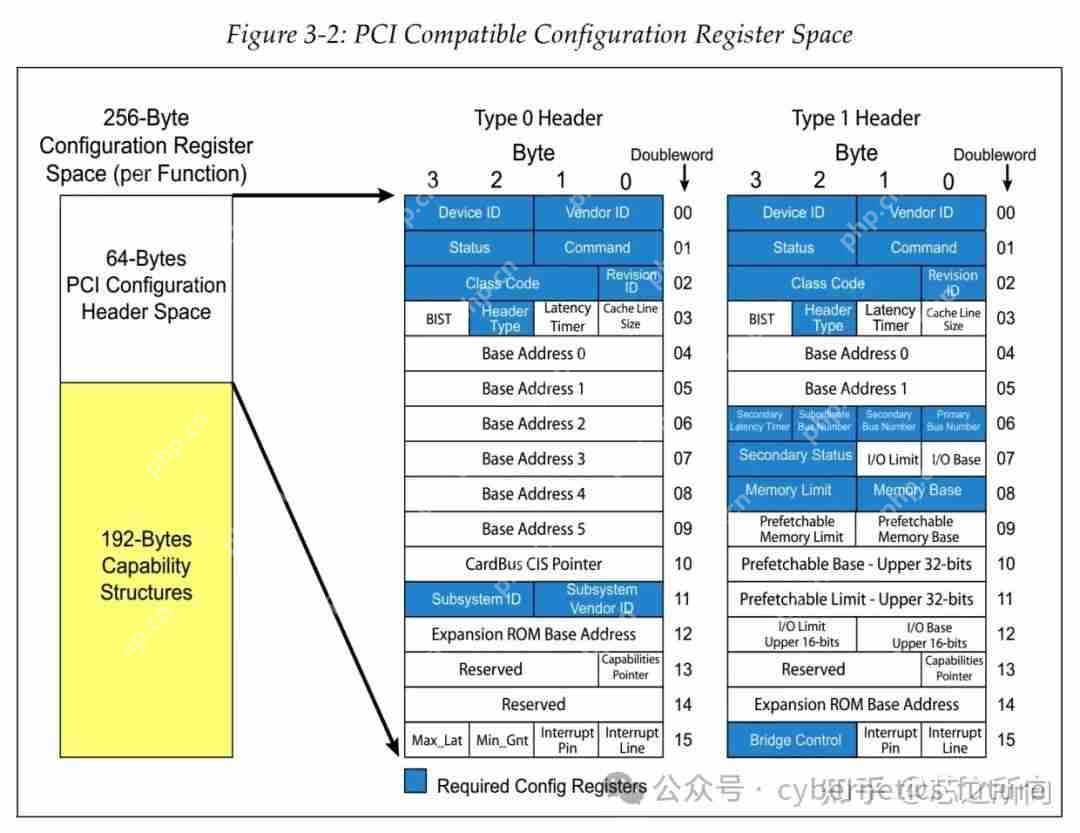 如图所示,在PCI-E配置空间的第16字节到第40字节,是所谓的BAR(Base Address Register),它是这些PCI-E设备本身的工作寄存器(如网卡的MAC寄存器、Phy寄存器等)地址段的起始地址和偏移量。这部分地址的访问方式与配置空间类似,也通过普通基址变址指令来访问,替代传统实模式下的input/output指令。
如图所示,在PCI-E配置空间的第16字节到第40字节,是所谓的BAR(Base Address Register),它是这些PCI-E设备本身的工作寄存器(如网卡的MAC寄存器、Phy寄存器等)地址段的起始地址和偏移量。这部分地址的访问方式与配置空间类似,也通过普通基址变址指令来访问,替代传统实模式下的input/output指令。
此外,操作系统在初始化PCI-E设备硬件时,会为PCI-E设备硬件分配自己可直接使用的DMA内存空间,硬件会直接对这部分空间进行数据的读写,因此CPU可以和其他PCI-E设备通过DMA内存地址空间,使用共享存储器的方式进行大批量数据的互通。
在物理机上,这些硬件直接看到的地址(物理机总线上可以通过逻辑分析仪抓到的地址,我们称为宿主机物理地址(HPA,Host Physical Address))。而程序指令中访问的地址为虚拟地址(HVA,Host Virtual Address),HVA是HPA通过MMU映射的结果,二者之间的映射表保存在MMU(Memory Management Unit)维护的TLB(Translation Lookaside Buffer)表中。对于多核处理器,大家共用一个MMU和TLB。
在存在虚拟机的情况下,问题变得复杂化。虚拟机上程序指令发出的地址被称为GVA(Guest Virtual Address)。问题在于,两台虚拟机有可能使用重叠的GVA,但实际上对应的HVA和HPA都不一样。那么,如何对二者进行区分呢?
Intel的方案是,采用EPT(extended page table),在MMU中的TLB增加虚拟机ID的字段,通过虚拟机ID和GVA的组合,来翻译得到HPA。
在ARM体系架构下,也有SMMU来实现这一翻译功能。
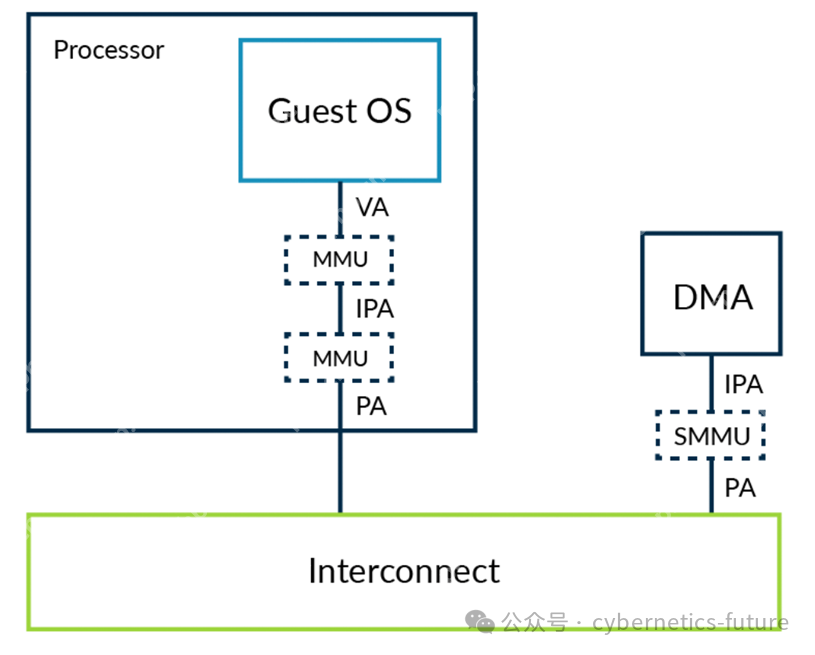 如图所示,在ARM下,地址翻译类似于Intel,也分为两个阶段:
如图所示,在ARM下,地址翻译类似于Intel,也分为两个阶段:
第一阶段,从虚拟机内部的虚拟地址(VA)到虚拟机认为的物理地址(IPA,Intermediate Physical Address);
第二阶段,根据虚拟机的ID,以及IPA,翻译得到真实物理地址(PA)。
对于PCI-E设备直通给虚拟机,我们需要将PCI-E设备的配置空间地址、IO BAR地址和DMA空间地址都通过SMMU进行转换成为VA后,虚拟机操作系统内的驱动程序就可以访问PCI-E设备的硬件了。
解决了PCI-E直通问题后,我们就可以在虚拟机中使用GPU了,也可以将一台服务器上的多个GPU通过虚拟机分配的方式,给不同的租户使用,并通过云计算平台按时长等方式进行收费。
然而,正所谓按下葫芦浮起瓢。这种GPU算力调度方式又遇到了新的问题——云原生。
请看下期分解。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。

相关文章
更多>>












热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 封神迷失手游排行榜-封神迷失手游下载-封神迷失游戏版本大全
- 2023幻灵双修手游排行榜-幻灵双修手游2023排行榜前十名下载
- 萌将风云游戏版本排行榜-萌将风云游戏合集-2023萌将风云游戏版本推荐
- 魔界军团排行榜下载大全-2023最好玩的魔界军团前十名推荐
- 王的崛起ios手游排行榜-王的崛起手游大全-有什么类似王的崛起的手游
- 天道仙尊游戏版本排行榜-天道仙尊游戏合集-2023天道仙尊游戏版本推荐
- 灵汐缘2手游2023排行榜前十名下载_好玩的灵汐缘2手游大全
- 口袋觉醒题材手游排行榜下载-有哪些好玩的口袋觉醒题材手机游戏推荐
- 龙之神途手游排行榜-龙之神途手游下载-龙之神途游戏版本大全
- 梦中的你手游排行榜-梦中的你手游下载-梦中的你游戏版本大全
- 永恒战士排行榜下载大全-2023最好玩的永恒战士前十名推荐
- 炎黄大陆手游排行榜-炎黄大陆手游下载-炎黄大陆游戏版本大全





