EfficientViT | 边缘设备上实时语义分割
efficientvit: 用于设备端语义分割的轻量级多尺度注意力论文链接:https: www php cn link e10
efficientvit: 用于设备端语义分割的轻量级多尺度注意力
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
论文链接:https://www.php.cn/link/e102943424a748e28068406f64765596代码链接:https://www.php.cn/link/8c9ce62eb00bfc39549c0b3cbe197ceb 演示
演示
摘要:在针对高分辨率视觉应用时,视觉变换器(ViT)不如卷积神经网络(CNN)表现出色。ViT 的关键计算瓶颈是 softmax 注意力模块,其计算复杂度与输入分辨率成二次方关系。降低 ViT 的成本以便在边缘设备上部署至关重要。现有的方法(如 Swin、PVT)通过将 softmax 注意力限制在局部窗口内或降低键/值张量的分辨率来降低成本,但这牺牲了 ViT 在全局特征提取方面的核心优势。EfficientViT 是一种高效的 ViT 架构,用于高分辨率、低计算成本的视觉识别。我们建议使用线性注意力替代 softmax 注意力,同时通过深度卷积增强其局部特征提取能力。EfficientViT 保持了全局和局部特征提取能力,同时享受线性计算复杂度。EfficientViT 是一个全新的轻量级多尺度注意力的语义分割模型系列。与之前的语义分割模型不同,这些模型依赖于沉重的自我关注、硬件效率低下的“大核”卷积或复杂拓扑结构来获得良好性能,而我们的轻量级多尺度注意力仅需轻量级和高效的硬件操作,就能实现全局感受野和多尺度学习(语义分割模型的两个关键特征)。在基准数据集上,EfficientViT 比以往最先进的语义分割模型有显著的性能提升,并在移动平台上显著提速。在 Cityscapes 上,我们的 EfficientViT 在不损失性能的情况下,在移动平台上的性能分别提高了 15 倍和 9.3 倍。与 SegNeXt 相比,移动延迟分别减少了 15 倍和 9.3 倍。在保持相同移动延迟的情况下,EfficientViT 在 ADE20K 上比 SegNeXt 增加了 7.4 mIoU。
贡献:将注意力机制的 softmax 平方复杂度降低到线性复杂度,同时引入深度卷积增强局部特征提取能力。 image-20230919102753047
image-20230919102753047
相关工作:基于 ViT 的模型、设备端高分辨率语义分割方法论:概述、轻量级多尺度注意力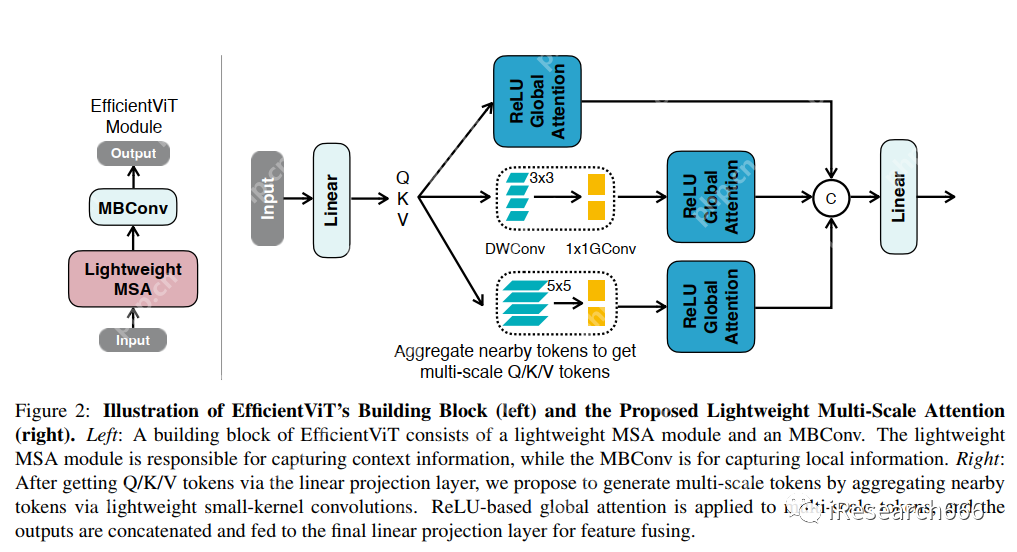 image-20230919102314552
image-20230919102314552
虽然线性注意力在计算复杂度和硬件延迟方面优于 softmax 注意力,但线性注意力有其局限性。以往的研究表明,在 NLP 中,线性注意力和 softmax 注意力之间通常存在显著的性能差距。对于视觉任务,之前的工作也表明线性注意力不如 softmax 注意力。线性注意力的劣势主要是由于局部特征提取能力的损失。如果没有 softmax 注意力中使用的非线性分数归一化,线性注意力很难像 softmax 注意力那样集中其注意力分布。给定相同的原始注意力分数,使用 softmax 比不使用 softmax 更能集中注意力。因此,线性注意力不能有效地集中在局部模式产生的高注意力分数,削弱了其局部特征提取能力。我们的想法是通过卷积来增强线性注意力,这在局部特征提取中非常有效。这样,我们就不需要依赖线性注意力来捕获局部特征,而可以专注于全局特征提取。具体来说,为了保持线性注意力的效率和简单性,我们建议在每个 FFN 层中插入一个深度卷积(DWConvGconv),这会产生很少的计算开销,同时大大提高线性注意力的局部特征提取能力。展示了增强型线性注意力的详细架构,它由一个线性注意力层和一个 FFN 层组成。将深度卷积插入 FFN 的中间。与之前的方法不同,我们在 EfficientViT 中不使用相对位置偏差。虽然相对位置偏差可以提高性能,但它使模型对分辨率变化很脆弱。多分辨率训练或新分辨率下的测试在检测和分割中很常见。去除相对位置偏差使 EfficientViT 对输入分辨率更加灵活。与以前的低计算 CNN 中的设计不同,我们为下采样块添加了额外的下采样 shortcuts。每个下采样 shortcut 由一个平均池化和一个 1x1 卷积组成。在我们的实验中,这些额外的下采样 shortcuts 可以稳定 EfficientViT 的训练并提高性能。
EfficientViT 架构: image-20230919102354273
image-20230919102354273
它由输入 stem 和 4 个阶段组成。最近的研究表明,在早期阶段使用卷积对 ViT 效果更好。我们遵循这个设计,并在第 3 阶段开始使用增强的线性注意力。为了突出高效的骨干本身,我们使用相同的扩展比 e 为 MBConv 和 FFN (e = 4),以保持超参数简单,所有深度卷积的核大小 k 相同(k = 5,除了输入 stem),以及所有层的相同激活函数(hard swish)。P2、P3 和 P4 表示阶段 2、3 和 4 的输出,形成特征图金字塔。我们按照惯例将 P2、P3 和 P4 馈送到检测头。我们使用 YoloX 进行检测。对于分割,我们融合了 P2 和 P4。在 Fast-SCNN 之后,融合的特征被馈送到包含多个卷积层的轻量级头部。对于分类,我们将 P4 馈送到轻量级头部,与 MobileNetV3 相同。
实验: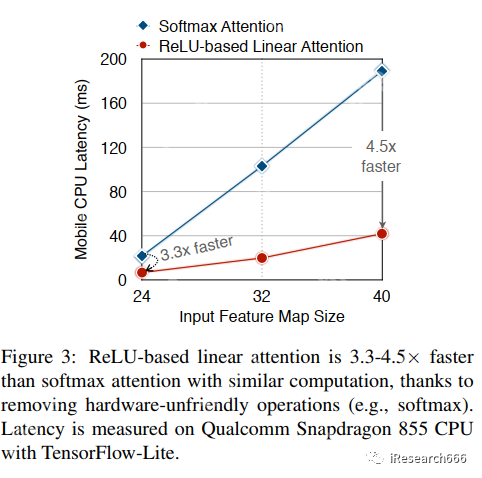 image-20230919104023799
image-20230919104023799
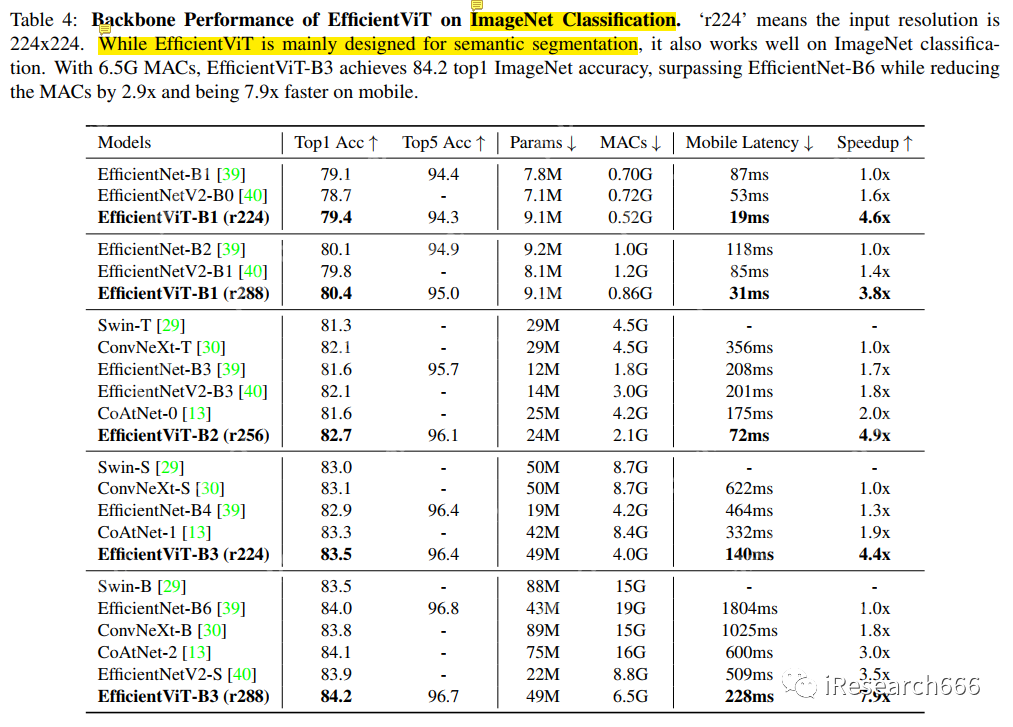
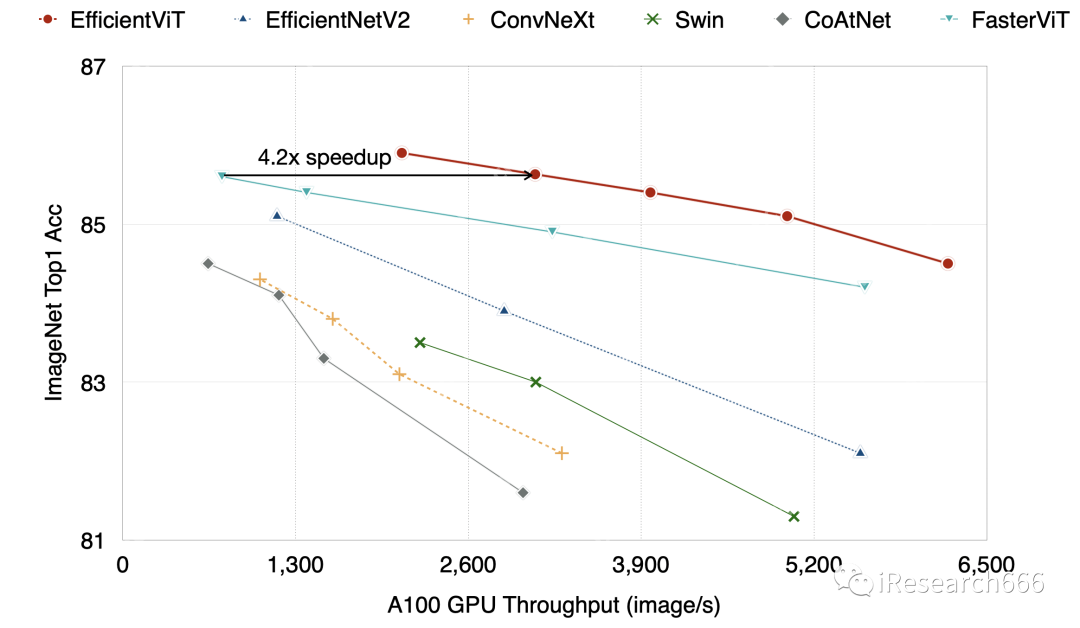
结论:主要是为语义分割任务设计的模型,但在图像分类任务 ImageNet 上不仅精度高,而且速度快(不是 SOTA,只是比较高而已,Top1 acc 排名 100 左右)。针对高分辨率场景,降低了 attention 的复杂度。针对边缘设备端分割模型的推理性能优化,达到实时推理的目的。金标准(Conv+Pseudo-MHSA 卷积加多头自注意力机制)的问题,至少可以说明两点,一是卷积的局部性+等变性的归纳偏置加 MHSA 的长距离表示能力;二是硬件和编译软件和运行软件对 CNN 支持的较好,对 transformer 还需要更多的支持。
参考文献
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。

相关文章
更多>>












热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 萌将风云游戏版本排行榜-萌将风云游戏合集-2023萌将风云游戏版本推荐
- 魔界军团排行榜下载大全-2023最好玩的魔界军团前十名推荐
- 王的崛起ios手游排行榜-王的崛起手游大全-有什么类似王的崛起的手游
- 天道仙尊游戏版本排行榜-天道仙尊游戏合集-2023天道仙尊游戏版本推荐
- 灵汐缘2手游2023排行榜前十名下载_好玩的灵汐缘2手游大全
- 口袋觉醒题材手游排行榜下载-有哪些好玩的口袋觉醒题材手机游戏推荐
- 龙之神途手游排行榜-龙之神途手游下载-龙之神途游戏版本大全
- 梦中的你手游排行榜-梦中的你手游下载-梦中的你游戏版本大全
- 永恒战士排行榜下载大全-2023最好玩的永恒战士前十名推荐
- 炎黄大陆手游排行榜-炎黄大陆手游下载-炎黄大陆游戏版本大全
- 山海夜行手游2023排行榜前十名下载_好玩的山海夜行手游大全
- 类似白蛇问仙的手游排行榜下载-有哪些好玩的类似白蛇问仙的手机游戏排行榜





