终于把知识蒸馏搞懂了!从DeepSeek R1到APT
知识蒸馏是什么?扩散模型的蒸馏和一般的蒸馏方法有什么不同?本文将简要介绍知识蒸馏的基本概念
知识蒸馏是什么?扩散模型的蒸馏和一般的蒸馏方法有什么不同?本文将简要介绍知识蒸馏的基本概念及其在扩散模型中的应用,希望能为相关领域的朋友提供一些参考。
关注腾讯云开发者,提前解锁一手技术干货?
01、知识蒸馏
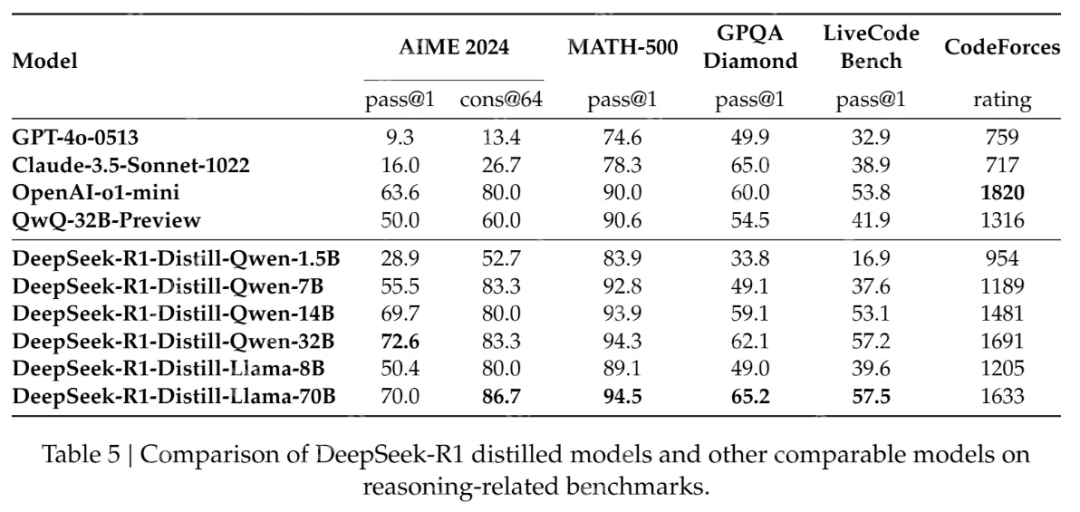
在春节期间,DeepSeek R1 公开发布了技术文档,并开源了多个蒸馏模型,其性能甚至超过了 OpenAI-o1-mini。这验证了通过简单的数据蒸馏将 671B 大模型的能力快速迁移到规模更小的模型的可行性。
那么,蒸馏模型和原始模型的区别是什么?它们之间有何关系?为什么使用大模型蒸馏后的小模型能比直接训练有更好的性能?要解释这些问题,我们需要从蒸馏原理开始讲起。
1.1 知识蒸馏的基本概念
知识蒸馏的过程可以简单解释为用教师模型教会学生模型知识。例如,在 DeepSeek R1 的例子中,DeepSeek R1 就是教师模型,用于蒸馏训练的小模型(如 Qwen 或 Llama)就是学生模型。知识蒸馏的核心在于让学生模仿教师的思考过程,而不仅仅是背诵答案。
硬标签 vs. 软标签
在蒸馏训练中,学生模型通常会接收两组不同的答案:人工训练集的 GT,即硬标签,以及教师模型生成的概率分布,即软标签:
硬标签就像是正确答案,例如告诉你这张图片是猫还是狗。软标签则包含了教师模型的概率分布,是更复杂的答案:“这个图片有80%的概率是猫,但也有20%的可能是狗,因为它们有点像”,这样模型不仅知道了答案,还学到了“猫和狗是比较容易混淆的”这个知识。在训练时,学生模型既看正确答案(保证正确性)又会看老师的软标签(学习老师的知识),这两个信号会“加权混合”成一个总目标。
为什么不全部使用软标签呢?
因为教师模型也有可能犯错!只使用软标签,学生模型的上限就是这个教师模型。
既然教师模型可能出错,为什么不筛选掉与硬标签冲突的错误标签呢?
因为软标签是模型生成的,量级通常比硬标签大得多,人工筛选每一个软标签的成本非常大。将软标签和硬标签混合使用并用权重控制比例是更合适的做法。如果教师模型比较值得信任,就可以调大它的权重,反之亦然。
温度参数
如果我们有一个比较精确的教师模型,它的输出可能是比较夸张化的,例如“这个图片有99%的概率是猫,有1%的可能是狗”,因为模型能很好地区分猫和狗。但是如果让模型更温柔一些,也许学生模型反而能更好地学到两者之间的关系。
这时候会引入温度参数 T 软化概率分布:
当 T>1 时,概率分布更平滑,保留类别间相对关系(如“猫 vs 狗”的相似性);当 T=1 时退化为标准 Softmax。DeepSeek R1 的蒸馏
在 DeepSeek R1 的实验报告中提到:

仅仅通过蒸馏 DeepSeek R1 的输出就可以让 R1-7N 模型的性能超越 GPT-4o-0513。其他更大的蒸馏模型就更强了。这里的 xxB 指的就是参数量,可以简单理解为参数量越大,模型计算力越强,天赋越好。而后天的训练就是对不同天赋的模型进行教学。DeepSeek R1 技术报告的蒸馏实验证明,对于天赋相同的模型(参数量和结构一致)用强力的大语言模型进行教学,比直接用人类知识教学更有效。在这里,蒸馏只用了 DeepSeek R1 的模型输出,并不涉及到更复杂的概率分布学习或者提供硬标签,就已经可以达到很好的效果了。
技术报告还提到一个有趣的观察点是,蒸馏后的模型如果继续用强化学习训练一段时间,可以进一步提高模型的性能。虽然他们没有开源这部分模型,不过这是一个很有意思的观察。可能学生在学习了教师模型之后,如果再强化学习一番,可以微调自己的知识结构,让其更适应自身的结构分布。
1.2 知识蒸馏 vs. 数据蒸馏
提了知识蒸馏的概念就顺便讲一下数据蒸馏。知识蒸馏学习的是教师模型的分布,而数据蒸馏侧重于通过数据增强等方法从数据的角度得到更纯净的训练数据来训练学生模型。数据蒸馏一般不涉及模型的压缩,而是对训练数据的精炼。
知识蒸馏和数据蒸馏的主要区别如下:

02、扩散模型的蒸馏和加速
说完了一般意义上的知识蒸馏,让我们回到文生图扩散模型上。和一般的蒸馏是为了压缩模型大小不太一样,在文生图领域里,蒸馏方法更多用在步数的蒸馏上。因为文生图扩散模型在生成图片时通常需要很多步的去噪步骤,我们对扩散模型更大的需求是压缩步数来达到用更少步数生成同样高质量的结果,甚至能达到一步生成。
需要先强调的是,扩散模型的加速不全是基于教师模型蒸馏的,蒸馏只是加速的手段之一。
对于扩散模型的加速,或者更准确地说,推理步骤的压缩,主要可以分为以下几类加速方法。
2.1 确定性加速方法 Consistency Model
以 LCM、LCM-LoRA 为代表的一致性模型加速方法,应该可以算是文生图领域中第一个有较大影响力的加速方法了。LCM 的原理详解推荐一篇博客:https://www.php.cn/link/3c053666271d0d4f874e31e15fbeb082。
简单来说,它重构了扩散模型的训练目标。之前模型生成,需要反复修改 n 次(n steps),但是 Consistency Model 要求无论从哪一步开始画,都要能直接预测最终的结果。所以 Consistency Model 可以用更少的步数生成去噪干净的图片。
Consistency Model 前面接一个 VAE 把图片转化成 latent 就变成了 Latent Consistency Model(LCM)。又因为这个训练是基于原始模型的微调,所以可以结合 LoRA 的技术,把微调的部分以 LoRA 的形式保存下来,既可以减小模型的大小,还可以和其他风格化 LoRA 进行组合。这也是第一个把加速技术做成 LoRA 模型的成功尝试。
流匹配 Flow Matching
扩散模型之所以需要多步生成,是因为它的 flow 是 curved 的,直接求解会有较大误差,Flow Matching 的核心思想就是让 Flow 变直,从而可以直接求解。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。

相关文章
更多>>


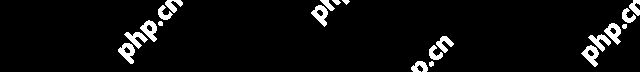







热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 剑指江湖题材手游排行榜下载-有哪些好玩的剑指江湖题材手机游戏推荐
- 九龙霸域手游排行榜-九龙霸域手游下载-九龙霸域游戏版本大全
- 天书传奇游戏排行-天书传奇所有版本-天书传奇游戏合集
- 至尊江湖游戏排行-至尊江湖所有版本-至尊江湖游戏合集
- 三国之魂手游排行-三国之魂免费版/单机版/破解版-三国之魂版本大全
- 独霸皇城手游排行榜-独霸皇城手游下载-独霸皇城游戏版本大全
- 魔龙大陆游戏版本排行榜-魔龙大陆游戏合集-2023魔龙大陆游戏版本推荐
- 斗破仙穹ios手游排行榜-斗破仙穹手游大全-有什么类似斗破仙穹的手游
- 斗破斩仙题材手游排行榜下载-有哪些好玩的斗破斩仙题材手机游戏推荐
- 沧元仙踪系列版本排行-沧元仙踪系列游戏有哪些版本-沧元仙踪系列游戏破解版
- 魅影再临ios手游排行榜-魅影再临手游大全-有什么类似魅影再临的手游
- 多种热门耐玩的魔刃OL破解版游戏下载排行榜-魔刃OL破解版下载大全





