AI网络爬虫:用deepseek提取百度文心一言的智能体数据
真实网址:https: www php cn link becbba75f70a129327afa2d6dfc4a1ac返回的json数据:{"errno"
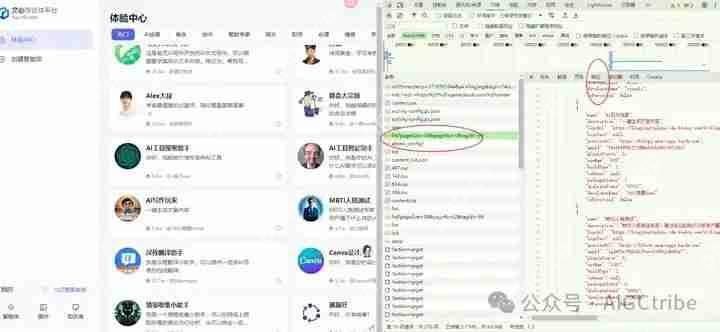 真实网址:https://www.php.cn/link/becbba75f70a129327afa2d6dfc4a1ac
真实网址:https://www.php.cn/link/becbba75f70a129327afa2d6dfc4a1ac
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
返回的json数据:{
"errno": 0,
"msg": "success",
"data": {
"total": 36,
"pageNo": 1,
"pageSize": 36,
"plugins": [
{
"name": "零基础学习路径规划",
"description": "你好,请你给出一个主题,我将给你一份完整的学习路径规划",
"logoUrl": "https://www.php.cn/link/e23909d8468ff4942ccea268fbbcafd1",
"logoText": {
"bgImage": "",
"labelValue": "1",
"color": 0,
"labelType": 2
},
"previewUrl": "https://www.php.cn/link/1b81139cc390ee1ce67042addf1d32cd",
"appId": "UjRqa5SBZzwvbRH8I06qp19H6OZdzjCR",
"pluginSource": 3,
"useNum": "786492",
"buildType": 1,
"isOwner": null,
"packageStatus": 6,
"dialogueCount": "2030481",
"developerName": "好想出去玩2020",
"isFavorited": false
},
deepseek中输入提示词:
你是一个Python编程专家,完成一个Python脚本编写的任务,具体步骤如下:
在F盘新建一个Excel文件:baiduaiagent20240619.xlsx
请求网址:
https://www.php.cn/link/becbba75f70a129327afa2d6dfc4a1ac请求方法:
GET
状态代码:
200 OK
获取网页的响应,这是一个嵌套的json数据;
获取json数据中"data"键的值,然后获取其中"plugins"键的值,这是一个json数据,提取这个json数据中所有的键写入Excel文件的表头 ,提取这个json数据中所有键对应的值写入Excel文件的列 ;
保存Excel文件;
注意:每一步都输出信息到屏幕;
每爬取1页数据后暂停5-9秒;
需要对 JSON 数据进行预处理,将嵌套的字典和列表转换成适合写入 Excel 的格式,比如将嵌套的字典转换为字符串;
在较新的Pandas版本中,append方法已被弃用。我们应该使用pd.concat来代替。
源代码:
import requestsimport pandas as pdimport timeimport json请求URL
url = "https://www.php.cn/link/becbba75f70a129327afa2d6dfc4a1ac"
请求头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"}
创建Excel文件
file_path = "F:/baiduaiagent20240619.xlsx"df = pd.DataFrame()
发送GET请求
response = requests.get(url, headers=headers)if response.status_code == 200:data = response.json()products = data['data']['plugins']
# 提取所有产品的键作为表头headers = set()for product in products: headers.update(product.keys())# 创建DataFrame并填充数据for product in products: product_data = {header: json.dumps(product.get(header, ''), ensure_ascii=False) if isinstance(product.get(header), (dict, list)) else product.get(header, '') for header in headers} new_data = pd.DataFrame([product_data]) df = pd.concat([df, new_data], ignore_index=True)print("Data processed.")登录后复制菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。
展开相关文章
更多>>













热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 御剑明神手游2023排行榜前十名下载_好玩的御剑明神手游大全
- 子弹骑士ios手游排行榜-子弹骑士手游大全-有什么类似子弹骑士的手游
- 大梦英雄排行榜下载大全-2023最好玩的大梦英雄前十名推荐
- 谋爱上瘾系列版本排行-谋爱上瘾系列游戏有哪些版本-谋爱上瘾系列游戏破解版
- 2023通天传奇手游排行榜-通天传奇手游2023排行榜前十名下载
- 神奇北港游戏排行-神奇北港所有版本-神奇北港游戏合集
- 多种热门耐玩的魔神之路破解版游戏下载排行榜-魔神之路破解版下载大全
- 黎明远征排行榜下载大全-2023最好玩的黎明远征前十名推荐
- 古剑沉默游戏排行-古剑沉默所有版本-古剑沉默游戏合集
- 苍翼之刃最新排行榜-苍翼之刃手游免费版下载-苍翼之刃免费破解版下载
- 2023决战沙城手游排行榜-决战沙城手游2023排行榜前十名下载
- 创世仙途排行榜下载大全-2023最好玩的创世仙途前十名推荐
热门攻略
更多>>





手机扫描此二维码,
在手机上查看此页面
版权投诉请发邮件到 cn486com#outlook.com (把#改成@),我们会尽快处理
Copyright © 2019-2020 菜鸟下载(www.cn486.com).All Reserved | 备案号:湘ICP备2023003002号-8
本站资源均收集整理于互联网,其著作权归原作者所有,如有侵犯你的版权,请来信告知,我们将及时下架删除相应资源