直逼DeepSeek-R1-32B,碾压李飞飞s1!UC伯克利等开源全新SOTA推理模型
新智元报道 编辑:编辑部 HNYZ【新智元导读】近日,斯坦福、UC伯克利等多机构联手发布了开

新智元报道
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
编辑:编辑部 HNYZ
【新智元导读】近日,斯坦福、UC伯克利等多机构联手发布了开源推理新SOTA——OpenThinker-32B,性能直逼DeepSeek-R1-32B。其成功秘诀在于数据规模化、严格验证和模型扩展。32B推理模型,仅用1/8数据,与同尺寸DeepSeek-R1打成平手!
就在刚刚,来自斯坦福、UC伯克利、华盛顿大学等机构联手发布了一款SOTA级推理模型——OpenThinker-32B,并同时开源了高达114k的训练数据。


项目主页:https://www.open-thoughts.ai/blog/scale
Hugging Face:https://huggingface.co/open-thoughts/OpenThinker-32B
数据集:https://huggingface.co/datasets/open-thoughts/OpenThoughts-114k
团队发现:采用经DeepSeek-R1验证标注(基于R1蒸馏)的大规模优质数据集,便可训练出SOTA的推理模型。
具体方法,就是通过数据规模化、推理过程验证以及模型规模扩展。
由此得到的OpenThinker-32B,在数学、代码和科学等多个基准测试中,OpenThinker-32B性能直接碾压了李飞飞团队s1和s1.1模型,直逼R1-Distill-32B。
值得一提的是,相比于使用了800k数据(包含600k个推理样本)的R1-Distill,OpenThinker-32B仅用了114k数据,就能拿下几乎同等的优异成绩。
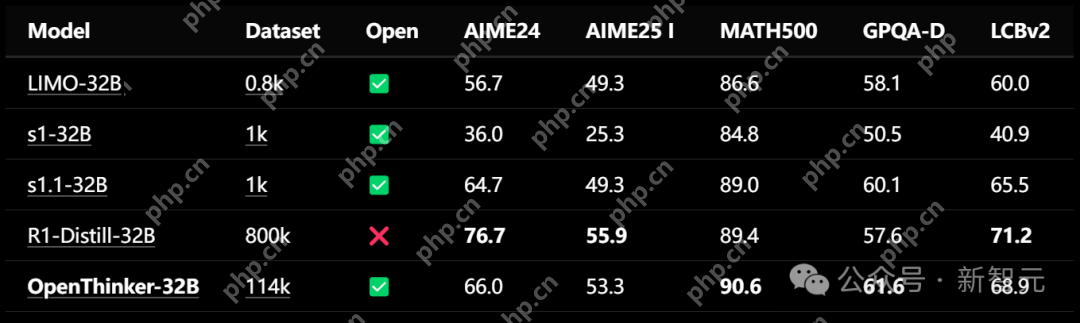
结果均通过开源评估框架Evalchemy计算得出
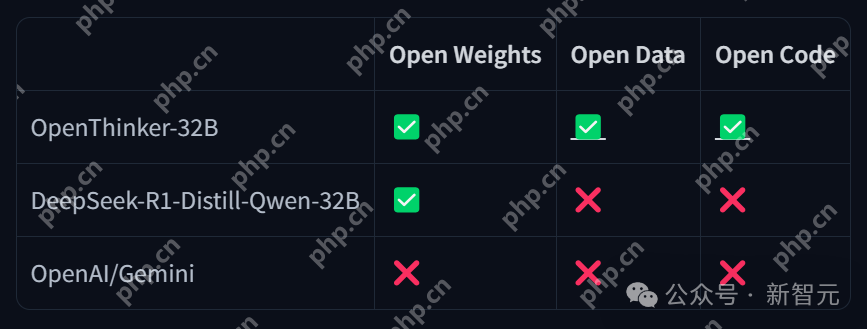
除此之外,OpenThinker-32还把模型权重、数据集、数据生成代码、训练代码上,全部都给公开了!
数据策展
研究人员使用了与之前训练OpenThinker-7B模型相同的OpenThoughts-114k数据集来训练OpenThinker-32B。
他们利用DeepSeek-R1模型,收集了精心挑选的17.3万个问题的推理过程和解答尝试。然后将这些原始数据作为OpenThoughts-Unverfied-173k数据集公开发布。
整个流程的最后一步是,如果推理过程未能通过验证,就过滤掉相应的数据样本。
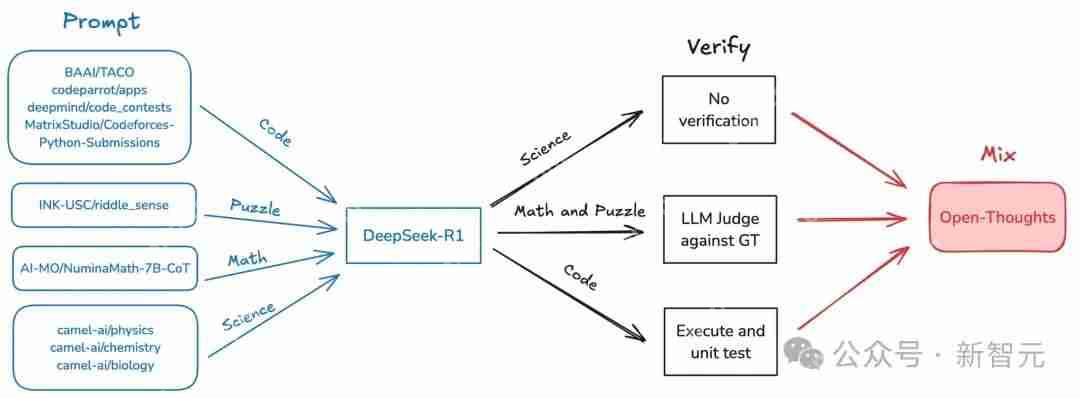
下图可视化地展示了整个过程。
研究团队首先输入源数据或问题提示,这些内容可以来自不同的领域和平台,如BAAI/TACO、DeepMind、Python提交等,涉及代码、谜题、科学和数学等多个方面。
接着这些多元的输入会进入核心的处理模块——DeepSeek-R1,在这里对数据进行分析与处理。这些问题会被分成三个方面,分别是:科学类问题、数学与谜题和代码。
有些结果不需要验证,可能是简单的分析或直接输出。对于一些需要深入验证的内容,利用大语言模型(LLM)采用与GT(Ground Truth)对比的方式进行评判。如果是代码,执行代码并进行单元测试,确保代码的正确性和有效性。
最后能将不同方向的结果结合起来,生成开放的思考和更为综合的解决方案。
研究团队更新了最终的OpenThoughts-114k数据集,加入了一个名为「metadata」的配置,其中包含了一些用于数据集构建的额外列:
problemground_truth_solutiontest_cases (code only)starter_code (code only)DeepSeek_reasoningDeepSeek_solutiondomainsource这些额外的元数据将使得这个数据集更容易用于新的场景,例如数据过滤、领域切换、验证检查以及更改推理过程的模板。
这些额外的元数据将得使该数据集使用起来更加容易,仅需一行代码就能完成例如过滤、更换领域、检查验证和更改推理跟踪模板等。
代码语言:javascript代码运行次数:0运行复制load_dataset("open-thoughts/OpenThoughts-114k", "metadata", split="train")菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。

相关文章
更多>>












热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 天道仙尊游戏版本排行榜-天道仙尊游戏合集-2023天道仙尊游戏版本推荐
- 灵汐缘2手游2023排行榜前十名下载_好玩的灵汐缘2手游大全
- 口袋觉醒题材手游排行榜下载-有哪些好玩的口袋觉醒题材手机游戏推荐
- 龙之神途手游排行榜-龙之神途手游下载-龙之神途游戏版本大全
- 梦中的你手游排行榜-梦中的你手游下载-梦中的你游戏版本大全
- 永恒战士排行榜下载大全-2023最好玩的永恒战士前十名推荐
- 炎黄大陆手游排行榜-炎黄大陆手游下载-炎黄大陆游戏版本大全
- 山海夜行手游2023排行榜前十名下载_好玩的山海夜行手游大全
- 类似白蛇问仙的手游排行榜下载-有哪些好玩的类似白蛇问仙的手机游戏排行榜
- 荒岛生存最新排行榜-荒岛生存手游免费版下载-荒岛生存免费破解版下载
- 圣武逍遥手游2023排行榜前十名下载_好玩的圣武逍遥手游大全
- 一念永恒最新排行榜-一念永恒手游免费版下载-一念永恒免费破解版下载
热门攻略
更多>>





手机扫描此二维码,
在手机上查看此页面
版权投诉请发邮件到 cn486com#outlook.com (把#改成@),我们会尽快处理
Copyright © 2019-2020 菜鸟下载(www.cn486.com).All Reserved | 备案号:湘ICP备2023003002号-8
本站资源均收集整理于互联网,其著作权归原作者所有,如有侵犯你的版权,请来信告知,我们将及时下架删除相应资源