DeepSeek与PyTorch携手:开启工业缺陷检测新时代(4/18)
摘要:本文介绍了如何结合deepseek和pytorch实现工业缺陷检测的全流程,重点聚焦于小样本数据增
摘要:本文介绍了如何结合deepseek和pytorch实现工业缺陷检测的全流程,重点聚焦于小样本数据增强、异常检测模型微调以及产线级部署与边缘计算优化。在小样本数据增强方面,我们探讨了多种方法,包括噪声注入、特征扰动、对比度增强、生成对抗网络(gans)、自回归模型(autoencoders)以及伪标签(pseudo-labeling)。这些方法能够有效扩充数据集,提升模型在有限数据条件下的泛化能力。
在异常检测模型微调方面,文章详细介绍了如何通过调整模型架构、优化训练策略以及利用迁移学习来提升模型对缺陷的识别能力。此外,通过对比学习数据增强(Mixup)等技术,模型能够在更具挑战性的数据分布中提升特征的鉴别能力。
最后,文章讨论了产线级部署与边缘计算优化。通过模型压缩技术,DeepSeek支持在工业网关等边缘设备上运行,实现毫秒级响应。在实际应用中,这种优化显著提升了生产效率,降低了维护成本,并提高了设备综合效率(OEE)。通过这些技术的结合,DeepSeek为工业缺陷检测提供了一个高效、可靠的解决方案。
在工业生产领域,工业缺陷检测是保障产品质量的关键环节,其重要性不言而喻。随着制造业的快速发展,对产品质量的要求日益严苛,缺陷检测成为确保产品符合标准、提升企业竞争力的核心要素。在电子制造中,微小的电路缺陷可能导致整个电子产品的故障,因此精确检测至关重要。

当前,工业缺陷检测面临着诸多严峻挑战。小样本数据问题尤为突出,在实际生产中,收集大量有缺陷的样本数据往往困难重重。某些高端制造业的产品良率极高,缺陷样本稀缺,这使得基于深度学习的传统检测模型难以获得充足的数据进行有效训练。因为深度学习模型通常需要大量的数据来学习特征和模式,小样本数据会导致模型的泛化能力不足,在面对新的检测任务时表现欠佳。
模型性能优化也是亟待解决的问题。工业生产环境复杂多变,对检测模型的准确性、实时性和稳定性都提出了极高要求。一方面,模型需要具备高准确率,能够精准识别各种类型和细微程度的缺陷;另一方面,要在保证精度的同时,实现快速检测,以满足生产线的高效运行需求。在高速生产线上,检测系统必须在短时间内完成大量产品的检测,否则会造成生产瓶颈。而在实际应用中,提高模型精度往往会增加计算复杂度,导致检测速度下降,如何平衡两者之间的关系是一大难题。
产线部署的复杂性同样不容忽视。将缺陷检测模型从实验室环境迁移到实际生产线上,需要考虑众多因素。生产环境中的噪声、振动、光照变化等都会对检测结果产生影响。此外,还需要与现有生产线的设备、系统进行无缝集成,确保整个生产流程的顺畅运行。不同厂家的设备接口、通信协议各不相同,如何实现检测系统与这些设备的有效对接,是产线部署过程中的一大挑战。
2.DeepSeek 与 PyTorch:技术基石
DeepSeek 作为人工智能领域的新兴力量,正以其独特的技术优势和创新理念,在工业缺陷检测等众多领域展现出巨大潜力。它基于先进的深度学习架构,具备强大的特征提取和模式识别能力,能够从复杂的数据中精准地捕捉到缺陷的特征信息。
在技术特点方面,DeepSeek 拥有高效的模型架构,通过优化的神经网络结构,实现了计算资源的合理利用,在保证检测精度的同时,有效提升了检测速度。其模型训练过程采用了先进的算法和策略,如动态知识蒸馏技术,使得模型在训练过程中能够快速收敛,减少训练时间和成本,同时还能提高模型的泛化能力,使其在面对不同场景和数据时都能保持稳定的性能表现 。
在自然语言处理任务中,DeepSeek 展现出强大的语义理解和生成能力,能够准确理解用户的问题,并生成高质量的回答。在图像识别领域,它可以精确识别各种复杂的图像特征,在工业缺陷检测中,无论是微小的划痕、裂纹,还是其他难以察觉的缺陷,DeepSeek 都能敏锐地捕捉到。在实际应用中,DeepSeek 已经在多个工业领域取得了显著成果。在电子制造行业,它帮助企业快速检测出电路板上的短路、断路等缺陷,大幅提高了产品质量和生产效率;在汽车制造领域,DeepSeek 能够对汽车零部件进行全面检测,及时发现潜在的质量问题,保障了汽车的安全性和可靠性。
2.2 PyTorch:深度学习框架的佼佼者PyTorch 是当下最受欢迎的深度学习框架之一,它以其卓越的灵活性和易用性,在深度学习领域占据着重要地位。PyTorch 基于 Python 语言开发,与 Python 的生态系统完美融合,这使得开发者可以利用 Python 丰富的库和工具,轻松地进行深度学习模型的开发和调试。
PyTorch 的动态计算图机制是其一大核心优势。与静态计算图不同,动态计算图允许在运行时构建和修改计算图,这使得模型的开发和调试更加直观和灵活。开发者可以像编写普通 Python 代码一样,根据实际需求动态地调整模型结构和计算过程,极大地提高了开发效率。在构建一个复杂的神经网络模型时,使用 PyTorch 可以方便地根据中间结果调整网络的连接方式或参数设置,而无需重新构建整个计算图。
自动求导功能也是 PyTorch 的重要特性。它能够自动计算张量(Tensor)的所有梯度,在神经网络训练过程中,自动求导系统可以根据定义好的计算图,自动计算出每个参数的梯度,从而大大简化了梯度计算的工作,让开发者能够更加专注于模型的设计和优化。在训练一个多层神经网络时,PyTorch 的自动求导功能可以自动计算出从输出层到输入层的所有梯度,使得模型的训练变得更加高效和便捷。

PyTorch 在工业缺陷检测中也发挥着重要作用。它提供了丰富的神经网络层和工具,方便开发者构建各种适合缺陷检测的模型。卷积神经网络(CNN)在图像特征提取方面具有强大的能力,PyTorch 中提供了完善的 CNN 相关模块,开发者可以利用这些模块快速搭建用于工业缺陷检测的 CNN 模型。PyTorch 还支持使用预训练模型进行迁移学习,在工业缺陷检测中,由于缺陷样本数据相对较少,使用预训练模型可以有效地利用大规模数据上学习到的特征,提高模型的泛化能力和检测性能。
3.小样本数据增强方案
在工业缺陷检测中,小样本数据问题犹如一座难以逾越的大山,严重制约着检测模型的性能。由于缺陷样本的获取困难,模型在训练时缺乏足够的数据来学习各种缺陷的特征和模式,这使得模型在面对新的缺陷样本时,很容易出现误判或漏判的情况。当模型训练数据中仅包含少量特定类型的划痕缺陷样本时,对于其他形状、尺寸或位置的划痕,以及新出现的缺陷类型,模型可能无法准确识别。
数据增强则是解决小样本数据问题的关键利器。通过对现有少量样本进行各种变换和处理,数据增强能够扩充数据集的规模和多样性,让模型接触到更多不同形态的样本,从而学习到更全面的特征信息,有效提升模型的泛化能力和鲁棒性。 经过数据增强,模型可以学习到不同角度、光照条件下的缺陷特征,即使在实际检测中遇到类似但不完全相同的缺陷,也能准确地进行判断。
3.2 常见的数据增强技术在工业缺陷检测中,常用的传统数据增强方法包括旋转、翻转、缩放和加噪声等,这些方法简单而有效,能够在一定程度上扩充数据集,提升模型的性能。
旋转是一种常见的数据增强方式,通过将图像绕其中心旋转一定角度,可以生成新的样本。在检测电路板上的元件缺陷时,将原始图像旋转 30 度、60 度等不同角度,能够模拟元件在不同安装角度下的情况,让模型学习到元件在各种角度下的正常与缺陷特征,提高模型对角度变化的适应性。
翻转包括水平翻转和垂直翻转,它可以改变图像的左右或上下方向,从而增加数据的多样性。对于一些具有对称性的产品,如金属板材,水平或垂直翻转后的图像与原始图像具有相似的特征,但又不完全相同,通过这种方式可以扩充数据集,使模型更好地学习到产品的对称特征以及缺陷在不同方向上的表现。
缩放是指对图像进行放大或缩小操作,通过改变图像的尺寸,可以模拟产品在不同距离或不同成像设备下的情况。在检测小型零部件时,将图像适当放大,能够突出零部件的细节特征,帮助模型更好地学习到微小缺陷的特征;而缩小图像则可以模拟远距离检测的情况,使模型具备对不同尺度下缺陷的检测能力。
加噪声则是在图像中添加各种类型的噪声,如高斯噪声、椒盐噪声等,以模拟实际检测过程中可能出现的干扰。在工业生产环境中,图像采集设备可能会受到电磁干扰、光线变化等因素的影响,导致采集到的图像存在噪声。通过在训练数据中添加噪声,可以让模型学习到在噪声环境下如何准确识别缺陷,提高模型的抗干扰能力。 如在检测汽车零部件表面缺陷时,添加高斯噪声后的图像更接近实际生产线上采集到的图像,模型在这种数据上训练后,能够更好地适应真实的检测环境。
生成对抗网络(GAN)作为一种强大的深度学习技术,在数据增强领域展现出了独特的优势。GAN 由生成器(Generator)和判别器(Discriminator)组成,生成器负责生成新的数据样本,判别器则用于判断生成的数据样本是真实的还是生成的。在训练过程中,生成器和判别器相互对抗、不断优化,使得生成器能够生成越来越逼真的数据样本。
在工业缺陷检测中,基于 GAN 的数据增强方法可以分为自动生成算法和半自动生成算法。自动生成算法如 DCGAN(深度卷积生成对抗网络)和 WGAN(瓦瑟斯坦生成对抗网络),能够直接输入噪声或少量缺陷样本,自动生成多张逼真的缺陷图像。DCGAN 通过引入深度卷积神经网络结构,取消了传统 GAN 中的全连接层和池化层,改用卷积层和转置卷积层,使得生成的图像更加清晰、细节更加丰富。在工业缺陷检测中,DCGAN 可以根据少量的缺陷样本,生成大量不同形态的缺陷图像,扩充数据集的规模。
WGAN 则通过改进距离度量方式,使用 Wasserstein 距离代替传统的 JS 散度,解决了传统 GAN 训练不稳定、模式崩溃等问题,使得生成的数据更加稳定、多样性更好。在实际应用中,WGAN 能够生成更加真实、多样化的缺陷样本,为模型训练提供更丰富的数据来源。
半自动生成算法如 CGAN(条件生成对抗网络)、CVAE(条件变分自编码器)和 Pix2Pix 等,需要人工交互给定一些信息,如缺陷生成的类别、形状等,然后根据这些信息生成指定类型的缺陷。CGAN 在生成器和判别器的输入中加入了额外的条件信息,通过控制这些条件信息,可以生成特定类别的缺陷图像。在检测电子元件的不同类型缺陷时,可以通过输入不同的条件信息,让 CGAN 生成对应类型的缺陷图像,从而有针对性地扩充特定类型缺陷的数据。
CVAE 结合了变分自编码器和生成对抗网络的思想,通过引入条件变量,能够在给定条件下生成具有特定特征的数据。在工业缺陷检测中,CVAE 可以根据缺陷的形状、大小等条件信息,生成符合要求的缺陷样本,为模型训练提供更具针对性的数据。
Pix2Pix 则是一种基于条件生成对抗网络的图像到图像转换模型,它可以将输入的图像按照指定的条件转换为目标图像。在工业缺陷检测中,可以利用 Pix2Pix 将正常图像转换为带有特定缺陷的图像,从而实现缺陷数据的增强。将正常的电路板图像转换为带有短路、断路等缺陷的图像,为模型训练提供更多的缺陷样本。
4.异常检测模型微调技巧
模型微调是迁移学习中的一种重要方法,它基于预训练模型,通过在特定任务的数据集上进行进一步训练,使模型能够更好地适应新任务。在工业缺陷检测中,预训练模型通常在大规模的通用图像数据集上进行训练,学习到了丰富的图像特征和模式。将这些预训练模型应用到工业缺陷检测任务时,由于缺陷数据的特殊性和多样性,直接使用预训练模型往往无法达到理想的效果。通过微调,可以利用预训练模型已经学习到的通用特征,针对工业缺陷数据进行优化,使模型能够更好地识别和分类各种缺陷。
模型微调能够有效解决工业缺陷检测中的数据量不足问题。由于获取大量的缺陷样本数据往往困难重重,从头开始训练一个模型容易导致过拟合,而微调可以在少量缺陷数据的基础上,对预训练模型进行调整,充分利用预训练模型在大规模数据上学习到的知识,提高模型在小样本数据上的性能。模型微调还可以提升模型的领域适应性,使模型更好地适应工业生产环境的复杂性和特殊性。
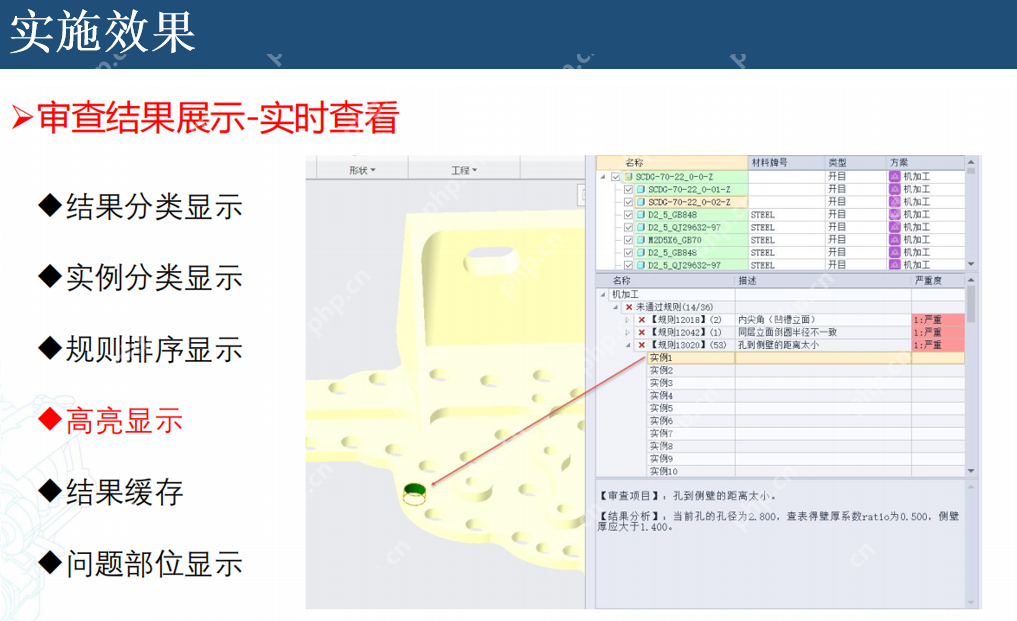
在 PyTorch 环境下对异常检测模型进行微调,需要遵循一系列严谨的步骤。首先是选择合适的预训练模型,这是微调的基础。在众多预训练模型中,如 VGG、ResNet、Inception 等,应根据工业缺陷检测任务的特点和需求进行选择。如果缺陷特征较为复杂,需要模型具备较强的特征提取能力,ResNet 等深层神经网络模型可能更为合适;而对于计算资源有限的场景,MobileNet 等轻量级模型则可能是更好的选择。
调整模型结构也是关键步骤之一。通常需要根据实际任务对预训练模型的最后几层进行修改,如替换分类层,以适应工业缺陷检测的类别数量。在检测电子元件的多种缺陷时,需要将预训练模型的分类层替换为能够输出对应缺陷类别的层。
设置合理的训练参数对模型性能有着重要影响。学习率是一个关键参数,它控制着模型在训练过程中参数更新的步长。如果学习率过大,模型可能会在训练过程中出现震荡,无法收敛;而学习率过小,则会导致训练速度过慢,甚至可能陷入局部最优解。在微调初期,可以尝试使用较大的学习率,快速接近最优解,随着训练的进行,逐渐减小学习率,以更精细地调整模型参数。常见的学习率调整策略有指数衰减、余弦退火等。
优化器的选择也不容忽视。常见的优化器如 SGD、Adam、RMSprop 等,各有其特点和适用场景。Adam 优化器结合了 Adagrad 和 RMSProp 的优点,能够自适应地调整学习率,在处理大规模数据集和高维度参数空间时表现出色,因此在工业缺陷检测模型的微调中被广泛应用。
防止过拟合是微调过程中的重要注意事项。过拟合会导致模型在训练集上表现良好,但在测试集和实际应用中性能大幅下降。为了防止过拟合,可以采用多种方法。增加训练数据是最直接有效的方法,通过数据增强技术扩充数据集,让模型学习到更多的特征和模式。添加 Dropout 层也是常用的手段,Dropout 层在训练过程中随机忽略一部分神经元,从而减少神经元之间的协同适应,降低过拟合的风险。L2 正则化则通过在损失函数中添加正则化项,对模型参数进行约束,防止参数过大导致过拟合。
为了更直观地展示微调模型在工业缺陷检测中的效果,我们以某汽车零部件表面缺陷检测项目为例进行分析。在该项目中,初始使用未经微调的预训练模型进行缺陷检测,模型在测试集上的准确率仅为 70%,召回率为 65%,对于一些微小的划痕和细微的裂纹等缺陷,漏检率较高。
随后,对预训练模型进行微调。选择在 ImageNet 数据集上预训练的 ResNet50 模型作为基础,根据汽车零部件表面缺陷的类别,将模型的最后分类层替换为能够输出对应缺陷类别的层。在训练过程中,采用 Adam 优化器,初始学习率设置为 0.001,并使用指数衰减策略调整学习率。同时,为了防止过拟合,对训练数据进行了旋转、翻转、加噪声等数据增强操作,并在模型中添加了 Dropout 层。
经过微调后,模型在测试集上的准确率提升到了 90%,召回率达到了 85%。在实际生产线上的应用中,模型能够准确地检测出各种类型的表面缺陷,包括之前容易漏检的微小划痕和细微裂纹,大大提高了产品质量检测的准确性和可靠性,有效减少了次品率,为企业带来了显著的经济效益。
5.产线级部署与边缘计算优化
将工业缺陷检测模型部署到生产线上,是实现工业智能化生产的关键一步,但这一过程充满了挑战。在生产线上,对检测系统的实时性要求极高。生产通常是连续进行的,产品在流水线上快速移动,检测系统必须在极短的时间内完成对产品的检测,否则会影响生产效率,导致生产停滞。在汽车零部件的生产线上,零部件以每分钟数十个甚至上百个的速度通过检测工位,检测系统需要在毫秒级的时间内判断出零部件是否存在缺陷,这对模型的推理速度提出了巨大挑战。
硬件资源限制也是不容忽视的问题。生产线上的设备空间有限,无法安装过于庞大和复杂的计算设备。而且,为了降低成本,企业往往希望在现有的硬件基础上进行部署,这就要求检测模型能够在有限的计算资源下高效运行。许多中小企业的生产线上,使用的是配置相对较低的工业计算机,其内存、CPU 性能等都无法与高端服务器相比,如何在这样的硬件条件下实现准确、快速的缺陷检测,是亟待解决的难题。
生产环境的复杂性也给产线级部署带来了诸多困难。生产现场存在各种噪声、振动、电磁干扰等因素,这些都可能影响检测设备的正常工作,导致检测结果不准确。生产线上的光照条件也可能不稳定,不同时间段、不同位置的光照强度和颜色都可能发生变化,这对基于视觉的工业缺陷检测模型来说,是一个巨大的挑战,因为光照变化可能会导致图像特征的改变,从而影响模型对缺陷的识别。
此外,产线级部署还需要考虑与现有生产线的兼容性和集成性。检测系统需要与生产线上的其他设备、控制系统进行无缝对接,实现数据的实时传输和共享,以确保整个生产流程的顺畅运行。在电子制造生产线上,检测系统需要与自动化装配设备、物料输送系统等协同工作,根据检测结果及时调整生产参数,实现生产过程的自动化控制。
5.2 边缘计算在工业缺陷检测中的应用边缘计算作为一种新兴的计算模式,为工业缺陷检测的产线级部署提供了有效的解决方案。边缘计算是指在靠近物或数据源头的一侧,采用网络、计算、存储、应用核心能力为一体的开放平台,就近提供最近端服务。其核心特点是将计算任务从云端转移到网络边缘的设备上进行处理,减少了数据传输的延迟和带宽需求。
在工业缺陷检测中,边缘计算的低延迟特性具有重要意义。由于边缘计算设备部署在靠近生产现场的位置,能够实时处理传感器采集到的数据,以毫秒级的速度做出响应。在检测高速移动的产品时,边缘计算可以在产品通过检测工位的瞬间完成缺陷检测,及时发现问题并采取相应措施,避免缺陷产品进入下一道工序,从而提高生产效率和产品质量。在手机屏幕的生产线上,屏幕以高速通过检测设备,边缘计算设备能够快速对屏幕图像进行分析,检测出是否存在亮点、坏点等缺陷,确保只有合格的屏幕进入后续的组装环节。
边缘计算还能减少数据传输量。在传统的云计算模式下,大量的原始数据需要传输到云端进行处理,这不仅消耗大量的网络带宽,还可能因为网络延迟而影响检测的实时性。而边缘计算可以在本地对数据进行预处理和分析,只将关键的检测结果传输到云端或其他控制系统,大大减少了数据传输量,降低了对网络带宽的依赖。在一个拥有数百个检测点的大型工厂中,如果每个检测点都将大量的原始图像数据传输到云端,网络带宽将面临巨大压力,而采用边缘计算后,大部分数据在本地处理,只有检测到的缺陷信息和相关统计数据被传输到云端,有效减轻了网络负担。
边缘计算还能提高系统的可靠性和安全性。由于数据在本地进行处理,减少了数据在传输过程中被窃取或篡改的风险,增强了数据的安全性。在工业生产中,产品质量数据和生产过程数据往往涉及企业的核心利益,边缘计算的本地处理和存储方式,为这些数据提供了更可靠的保护。即使在网络连接中断的情况下,边缘计算设备也能继续独立工作,保证生产的连续性。在一些偏远地区或网络信号不稳定的工厂,边缘计算的这一优势尤为突出,它可以确保检测系统在各种复杂的网络环境下都能正常运行。
为了充分发挥边缘计算在工业缺陷检测中的优势,需要采取一系列优化策略。边缘计算设备的选型至关重要。应根据生产现场的具体需求和环境条件,选择合适的硬件设备。对于对计算性能要求较高的场景,可以选择配备高性能 CPU、GPU 或 NPU 的边缘计算设备,如瑞芯微 RK3588 AI 边缘计算盒子,它采用旗舰级高端处理器,拥有 8 核 CPU 和 6T 算力 NPU,能够快速处理复杂的图像数据,适用于对检测精度和速度要求较高的工业缺陷检测任务。而对于空间有限、功耗要求较低的场景,则可以选择小型化、低功耗的设备,如恩智浦 i.MX9532 工业边缘计算网关开发板,它集成了 2 个 Cortex - A55 核和 1 个 Crtex - M33 实时核,具备低功耗、高性能的特点,且尺寸小巧,便于在空间有限的生产线上部署。
算法优化也是提高边缘计算性能的关键。在边缘计算环境下,由于计算资源相对有限,需要对检测算法进行优化,以提高算法的执行效率和准确性。可以采用轻量化的神经网络模型,如 MobileNet、ShuffleNet 等,这些模型通过优化网络结构,减少了模型的参数数量和计算量,在保证一定检测精度的前提下,能够在边缘设备上快速运行。还可以运用模型剪枝、量化等技术,对模型进行压缩和优化。模型剪枝通过去除神经网络中不重要的连接和神经元,减少模型的复杂度,从而降低计算量;量化则是将模型中的参数和计算过程用低精度的数据表示,如将 32 位浮点数转换为 8 位整数,这样可以在不显著影响模型精度的情况下,大大减少内存占用和计算时间。在实际应用中,对一个基于 ResNet 的工业缺陷检测模型进行剪枝和量化处理后,模型的大小减小了 50%,推理速度提高了 30%,同时检测精度仅下降了 2%,在边缘计算设备上取得了更好的性能表现。
模型压缩技术也是提升边缘计算效率的重要手段。除了上述的剪枝和量化技术外,还可以采用知识蒸馏等方法。知识蒸馏是将一个复杂的大模型(教师模型)的知识转移到一个简单的小模型(学生模型)上,使小模型能够学习到大模型的特征表示和分类能力。在工业缺陷检测中,通过知识蒸馏,可以将在大规模数据集上训练的复杂模型的知识传递给适合在边缘设备上运行的小模型,从而提高小模型的性能。将一个在大型图像数据集上训练的深度卷积神经网络作为教师模型,将一个轻量级的 MobileNet 作为学生模型,通过知识蒸馏,MobileNet 在工业缺陷检测任务上的准确率提高了 10%,同时保持了较低的计算复杂度,能够在边缘设备上高效运行。通过综合运用这些边缘计算优化策略,可以有效提升工业缺陷检测系统在生产线上的性能和效率,实现工业生产的智能化和自动化。
6.实战案例与经验分享
在某电子制造企业的生产线上,主要生产手机主板,随着市场竞争的加剧和对产品质量要求的不断提高,传统的人工目检方式已无法满足生产需求。人工检测不仅效率低下,容易受主观因素影响,导致漏检和误检率较高,而且随着企业产能的提升,人工成本也在不断增加。
为了解决这些问题,企业决定引入基于深度学习的工业缺陷检测系统,目标是实现手机主板表面缺陷的自动化、高精度检测,提高检测效率和准确率,降低次品率,同时减少人工成本。具体期望达到的指标包括:缺陷检测准确率达到 95% 以上,召回率达到 90% 以上,检测速度满足生产线每分钟处理 30 块主板的要求。
6.2 技术方案实施过程在项目中,首先采用了 DeepSeek 强大的特征提取能力,对手机主板图像进行特征提取。结合 PyTorch 深度学习框架,搭建了基于卷积神经网络(CNN)的缺陷检测模型。
针对小样本数据问题,采用了数据增强技术。对少量的缺陷样本图像进行旋转、翻转、缩放和加噪声等操作,扩充数据集规模。还利用基于生成对抗网络(GAN)的自动生成算法,如 DCGAN,输入少量缺陷样本,生成了大量逼真的缺陷图像,进一步丰富了数据集,使模型能够学习到更多不同形态的缺陷特征。
在模型微调阶段,选择在 ImageNet 数据集上预训练的 ResNet18 模型作为基础。根据手机主板缺陷检测的类别,对模型的最后几层进行了修改,替换为能够输出对应缺陷类别的层。在训练过程中,使用 Adam 优化器,初始学习率设置为 0.0001,并采用余弦退火策略调整学习率。为防止过拟合,对训练数据进行了数据增强,并在模型中添加了 Dropout 层,同时使用 L2 正则化对模型参数进行约束。
在产线级部署方面,考虑到生产线的实时性要求和硬件资源限制,采用了边缘计算方案。选择了英伟达 Jetson Xavier NX 边缘计算设备,它具有强大的计算能力和低功耗特性,适合在生产线上部署。为了优化边缘计算性能,对检测算法进行了优化,采用了轻量化的神经网络模型 MobileNetV2,并运用模型剪枝和量化技术对模型进行压缩和优化。经过剪枝和量化处理后,模型的大小减小了 40%,推理速度提高了 25%,在边缘计算设备上能够快速、准确地运行。
6.3 项目成果与经验总结经过项目团队的努力,成功实现了手机主板表面缺陷检测系统的部署和应用。在实际运行中,系统的缺陷检测准确率达到了 96%,召回率达到了 92%,检测速度达到了每分钟处理 35 块主板,完全满足了项目的预期目标。通过该系统的应用,企业的次品率显著降低,从原来的 5% 降低到了 2% 以下,有效提高了产品质量和市场竞争力。人工成本也大幅减少,原本需要 10 名检测人员的工作,现在仅需 2 名技术人员进行设备维护和监控,为企业节省了大量的人力成本。
在项目实施过程中,也积累了宝贵的经验教训。数据质量和数量对模型性能至关重要,在数据收集和增强阶段,要尽可能地保证数据的真实性和多样性,以提高模型的泛化能力。模型微调时,需要仔细选择预训练模型和调整参数,充分考虑任务的特点和需求,避免盲目调整导致模型性能下降。产线部署时,要充分考虑硬件设备的选型和算法优化,确保系统在复杂的生产环境中能够稳定、高效地运行。与生产线其他设备和系统的集成也需要提前规划和测试,确保整个生产流程的顺畅。
以下是针对《DeepSeek+PyTorch:工业缺陷检测全流程》的三个相关代码案例,分别涵盖小样本数据增强方案、异常检测模型微调技巧以及产线级部署与边缘计算优化:
1. 小样本数据增强方案以下代码展示了如何使用PyTorch实现小样本数据增强,通过数据增强技术扩充工业缺陷检测数据集:
代码语言:javascript代码运行次数:0运行复制import torchimport torchvision.transforms as transformsfrom torchvision.datasets import ImageFolderfrom torch.utils.data import DataLoader# 定义数据增强的转换操作transform = transforms.Compose([ transforms.RandomHorizontalFlip(), transforms.RandomRotation(15), transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 加载数据集并应用数据增强dataset = ImageFolder(root="path/to/your/dataset", transform=transform)dataloader = DataLoader(dataset, batch_size=32, shuffle=True)# 示例:打印增强后的数据for images, labels in dataloader: print(images.shape, labels) break
以下代码展示了如何使用PyTorch对预训练模型进行微调,以适应工业缺陷检测任务:
代码语言:javascript代码运行次数:0运行复制import torchimport torch.nn as nnimport torchvision.models as models# 加载预训练模型(例如ResNet)model = models.resnet50(pretrained=True)# 替换最后的全连接层以适应新的分类任务num_classes = 2 # 假设二分类:正常和缺陷model.fc = nn.Linear(model.fc.in_features, num_classes)# 定义损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 微调模型for epoch in range(10): # 假设训练10个epoch model.train() for images, labels in dataloader: optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() print(f"Epoch {epoch+1}, Loss: {loss.item()}")以下代码展示了如何将模型导出为ONNX格式,并在边缘设备上进行优化:
代码语言:javascript代码运行次数:0运行复制import torchimport torch.onnx as onnx# 假设模型已经训练完成model.eval()# 创建一个虚拟输入dummy_input = torch.randn(1, 3, 224, 224)# 导出模型为ONNX格式onnx.export(model, dummy_input, "model.onnx", opset_version=11)# 使用ONNX Runtime进行推理(需要安装onnxruntime库)import onnxruntime as ort# 加载ONNX模型session = ort.InferenceSession("model.onnx")# 准备输入数据input_name = session.get_inputs()[0].nameoutput_name = session.get_outputs()[0].name# 运行推理output = session.run([output_name], {input_name: dummy_input.numpy()})print(output)这些代码案例展示了如何结合DeepSeek和PyTorch实现工业缺陷检测全流程中的关键步骤,包括数据增强、模型微调和边缘部署优化。
7.未来展望与发展趋势
在未来,DeepSeek 和 PyTorch 等技术将在工业缺陷检测领域持续创新,引领技术发展的新潮流。
模型架构的创新将是提升检测性能的关键方向之一。研究人员可能会开发出更加先进的神经网络架构,进一步提高模型的特征提取能力和表达能力。结合 Transformer 架构和卷积神经网络的优势,创造出能够更好地处理图像序列和长距离依赖关系的新型架构,以应对工业缺陷检测中复杂多变的缺陷特征。通过引入注意力机制、自监督学习等技术,使模型能够更加智能地关注图像中的关键区域,自动学习到更有效的缺陷特征表示,从而提高检测的准确性和鲁棒性。
数据增强方法也将不断演进,朝着更加智能化、多样化的方向发展。除了现有的基于生成对抗网络(GAN)的数据增强技术外,未来可能会出现基于强化学习、迁移学习等技术的数据增强方法。基于强化学习的数据增强可以让模型根据检测任务的需求,自动生成最具挑战性和代表性的数据样本,从而提高模型在复杂场景下的泛化能力。迁移学习则可以利用其他相关领域的大量数据,为工业缺陷检测提供更多的知识和信息,进一步扩充数据集的规模和多样性。
多模态数据融合技术也将在工业缺陷检测中发挥越来越重要的作用。目前的工业缺陷检测主要依赖于视觉数据,但在实际生产中,产品的缺陷往往会伴随着其他物理量的变化,如声音、温度、振动等。未来,通过融合视觉、声学、热学等多种模态的数据,可以从多个角度获取产品的状态信息,从而更全面、准确地检测出缺陷。在检测汽车发动机的缺陷时,不仅可以通过视觉图像观察发动机的外观和结构,还可以利用声学传感器检测发动机运行时的声音特征,以及通过热传感器监测发动机的温度分布,综合分析这些多模态数据,能够更有效地发现发动机内部的潜在缺陷。
7.2 应用拓展前景工业缺陷检测技术的应用前景极为广阔,将在众多行业中发挥重要作用,推动工业生产向智能化、高效化方向升级。
在制造业中,工业缺陷检测技术将得到更广泛的应用。除了现有的电子制造、汽车制造等行业,在航空航天、机械制造、医疗器械等领域,对产品质量和安全性的要求极高,工业缺陷检测技术将成为保障产品质量的关键手段。在航空航天领域,飞机零部件的任何微小缺陷都可能引发严重的安全事故,因此对缺陷检测的精度和可靠性要求近乎苛刻。通过采用先进的工业缺陷检测技术,可以对飞机发动机叶片、机身结构件等关键零部件进行全面、精确的检测,及时发现潜在的缺陷,确保飞机的飞行安全。
随着新能源产业的快速发展,工业缺陷检测技术在新能源领域也将迎来新的机遇。在太阳能电池板制造、锂电池生产等环节,产品的质量直接影响到能源转换效率和使用寿命。利用工业缺陷检测技术,可以对太阳能电池板的表面缺陷、锂电池的电极缺陷等进行快速、准确的检测,提高产品的良品率,降低生产成本,推动新能源产业的健康发展。
在智能工厂的建设中,工业缺陷检测技术将是实现生产过程自动化和智能化的重要组成部分。通过与物联网、大数据、云计算等技术的深度融合,工业缺陷检测系统可以实时采集生产线上的产品数据,并将检测结果反馈给生产控制系统,实现生产过程的实时监控和自动调整。当检测到产品存在缺陷时,系统可以自动发出警报,并指导生产线进行相应的调整和修复,从而提高生产效率和产品质量,降低生产成本。
工业缺陷检测技术还将在质量追溯和供应链管理中发挥重要作用。通过对产品缺陷数据的分析和挖掘,可以追溯缺陷产生的源头,找出生产过程中的薄弱环节,为企业改进生产工艺、优化产品设计提供依据。在供应链管理中,工业缺陷检测技术可以确保原材料和零部件的质量,防止不合格产品进入生产环节,保障整个供应链的稳定运行。
工业缺陷检测技术在未来将展现出巨大的发展潜力和应用价值,为工业生产的智能化升级和可持续发展提供强大的技术支持。
8.结论
在工业生产智能化的进程中,工业缺陷检测扮演着举足轻重的角色。DeepSeek 与 PyTorch 的结合,为攻克工业缺陷检测中的诸多难题提供了强有力的技术支撑,展现出了巨大的应用价值。
通过数据增强技术,尤其是基于生成对抗网络(GAN)的创新方法,能够有效扩充小样本数据集,显著提升模型的泛化能力,使其在面对复杂多样的缺陷样本时,依然能够保持稳定且准确的检测性能。模型微调技巧则充分利用了预训练模型的优势,通过合理的参数调整和结构优化,使模型能够快速适应工业缺陷检测的特定任务,在有限的数据条件下,实现检测性能的大幅提升。在产线级部署方面,边缘计算的应用有效解决了实时性和硬件资源限制等关键问题,通过精心的设备选型和算法优化,确保了检测系统在复杂生产环境中的高效、稳定运行。
实际项目案例充分证明了 DeepSeek 与 PyTorch 结合的有效性和可行性,为企业带来了显著的经济效益和质量提升。展望未来,随着技术的不断创新和发展,工业缺陷检测领域将迎来更多的突破和机遇。希望广大读者能够积极探索和实践这些技术,将其应用到更多的工业场景中,共同推动工业生产向智能化、高质量化方向迈进。

感谢您耐心阅读本文。希望本文能为您提供有价值的见解和启发。如果您对[Windows+docker本地部署DeepSeek-R1]有更深入的兴趣或疑问,欢迎继续关注相关领域的最新动态,或与我们进一步交流和讨论。让我们共同期待[Windows+docker本地部署DeepSeek-R1]在未来的发展历程中,能够带来更多的惊喜和突破。
再次感谢,祝您拥有美好的一天!
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。

相关文章
更多>>





热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 超级联盟ios手游排行榜-超级联盟手游大全-有什么类似超级联盟的手游
- 多种热门耐玩的倾世名姬破解版游戏下载排行榜-倾世名姬破解版下载大全
- 血色征途最新排行榜-血色征途手游免费版下载-血色征途免费破解版下载
- 多种热门耐玩的死神逃生破解版游戏下载排行榜-死神逃生破解版下载大全
- 萝莉塔防排行榜下载大全-2023最好玩的萝莉塔防前十名推荐
- 剑斩烈焰题材手游排行榜下载-有哪些好玩的剑斩烈焰题材手机游戏推荐
- 我欲修仙手游2023排行榜前十名下载_好玩的我欲修仙手游大全
- 剑气修真最新排行榜-剑气修真手游免费版下载-剑气修真免费破解版下载
- 魔刃OL手游排行-魔刃OL免费版/单机版/破解版-魔刃OL版本大全
- 仙元天下手游排行-仙元天下免费版/单机版/破解版-仙元天下版本大全
- 梦话西游游戏版本排行榜-梦话西游游戏合集-2023梦话西游游戏版本推荐
- 类似头号粉丝的游戏排行榜_有哪些类似头号粉丝的游戏
热门攻略
更多>>





手机扫描此二维码,
在手机上查看此页面
版权投诉请发邮件到 cn486com#outlook.com (把#改成@),我们会尽快处理
Copyright © 2019-2020 菜鸟下载(www.cn486.com).All Reserved | 备案号:湘ICP备2023003002号-8
本站资源均收集整理于互联网,其著作权归原作者所有,如有侵犯你的版权,请来信告知,我们将及时下架删除相应资源