DeepSeek R1&V3 原版论文摘要
《deepseek-r1:通过强化学习激励法学硕士的推理能力》论文原文:https: www php cn link 65d1b
《deepseek-r1:通过强化学习激励法学硕士的推理能力》
论文原文:https://www.php.cn/link/65d1b8a382fe0421b1c1d5b932baf87a
论文提要
引言
- 背景:近年来,大型语言模型(LLMs)在快速迭代和进化,逐渐缩小了与通用人工智能(AGI)之间的差距。后训练(post-training)已经成为完整训练流程中的一个重要组成部分,能够提升模型在推理任务上的准确性、与社会价值观的对齐以及对用户偏好的适应性。
- 问题:尽管OpenAI的o1系列模型通过扩展链式推理(CoT)过程在多种推理任务中取得了显著改进,但如何有效实现测试时扩展仍然是一个开放性问题。
- 目标:论文的目标是通过纯强化学习(RL)提升语言模型的推理能力,探索LLMs在没有任何监督数据的情况下,通过自我进化发展推理能力的潜力。
方法
- 2.1 概述:论文展示了即使不使用监督微调(SFT)作为冷启动,通过大规模强化学习(RL)也可以显著提升推理能力。进一步引入少量冷启动数据可以进一步提升性能。
- 2.2 DeepSeek-R1-Zero:在基础模型上应用强化学习
- 强化学习算法:采用GRPO(Group Relative Policy Optimization)算法,避免使用与策略模型大小相同的批评者模型,通过组分数估计基线。
- 奖励建模:采用基于规则的奖励系统,包括准确性奖励和格式奖励。
- 训练模板:设计了一个简单的模板,要求模型首先生成推理过程,然后提供最终答案。
- 性能:DeepSeek-R1-Zero在AIME 2024基准测试中表现出色,pass@1分数从15.6%提升至71.0%,通过多数投票进一步提升至86.7%,与OpenAI-o1-0912相当。
- 2.3 DeepSeek-R1:带有冷启动的强化学习
- 冷启动:通过收集数千个长CoT数据微调基础模型,作为RL的起点。
- 推理导向的强化学习:在微调后的模型上应用与DeepSeek-R1-Zero相同的RL训练过程。
- 拒绝采样和监督微调:在RL收敛后,通过拒绝采样生成新的SFT数据,并结合其他领域的数据进行微调。
- 面向所有场景的强化学习:在最终阶段,对模型进行额外的RL训练,优化其在各种场景下的表现。
- 2.4 蒸馏:赋予小型模型推理能力:使用DeepSeek-R1作为教师模型,通过蒸馏将推理能力传递给小型密集模型,显著提升了这些模型的推理能力。
实验
- 基准测试:在MMLU、MMLU-Pro、GPQA Diamond、SimpleQA、LiveCodeBench、Codeforces等多个基准测试中评估模型性能。
- 评估提示:使用零样本提示,避免少样本提示对性能的负面影响。
- 基线模型:与DeepSeek-V3、Claude-Sonnet-3.5-1022、GPT-4o-0513、OpenAI-o1-mini等模型进行比较。
- 评估设置:使用pass@??评估方法,生成多个响应并计算平均准确性。
讨论
- 蒸馏与强化学习:蒸馏方法在提升小型模型推理能力方面表现出色,而直接在小型模型上应用RL则需要更多的计算资源。
- 未成功的尝试:探索了过程奖励模型(PRM)和蒙特卡洛树搜索(MCTS),但这些方法在大规模训练中面临挑战。
结论、局限性和未来工作
- 结论:DeepSeek-R1通过强化学习显著提升了推理能力,与OpenAI-o1-1217相当。
- 局限性:DeepSeek-R1在某些任务(如函数调用、多轮对话)上的表现不如DeepSeek-V3,且存在语言混杂问题。
- 未来工作:计划进一步提升模型的通用能力,优化语言混杂问题,并探索更高效的训练方法。论文还开源了DeepSeek-R1-Zero、DeepSeek-R1以及基于Qwen和Llama的多个蒸馏模型,为研究社区提供了宝贵的资源。

《DeepSeek-V3 技术报告》
论文原文:https://www.php.cn/link/9a9507ccbb6be14e614c0c61cb485c83
研究背景近年来,大型语言模型(LLMs)在人工智能领域取得了快速的发展,逐渐接近通用人工智能(AGI)。开源模型如 DeepSeek 系列、LLaMA 系列等也在不断进步,努力缩小与闭源模型的差距。为了进一步提升开源模型的能力,研究者们推出了 DeepSeek-V3,这是一个参数规模更大的 MoE 模型,旨在通过高效的架构和训练策略实现更强的性能。
研究方法DeepSeek-V3 的架构基于以下关键技术和策略:
- Multi-head Latent Attention (MLA) 和 DeepSeekMoE:这两种架构在 DeepSeek-V2 中已经得到验证,能够实现高效的推理和成本效益的训练。
- 无辅助损失的负载平衡策略:通过动态调整专家的负载,避免了因负载平衡而导致的性能下降。
- 多 token 预测训练目标:通过预测多个未来 token 来增强模型性能。
- FP8 混合精度训练:首次在大规模模型上验证了 FP8 训练的有效性,显著降低了 GPU 内存使用量并加速了训练。
- 高效的训练框架:包括 DualPipe 算法和跨节点 All-to-All 通信的优化,减少了通信开销并提高了训练效率。
实验与结果DeepSeek-V3 在 14.8 万亿高质量和多样化的 token 上进行了预训练,并通过监督微调(SFT)和强化学习(RL)阶段进一步优化。在多个基准测试中,DeepSeek-V3 的表现超过了其他开源模型,并与领先的闭源模型(如 GPT-4o 和 Claude-3.5-Sonnet)相当。具体表现如下:
- 知识类基准测试:在教育基准测试(如 MMLU、MMLU-Pro 和 GPQA)中,DeepSeek-V3 的表现优于所有其他开源模型,与 GPT-4o 和 Claude-Sonnet-3.5 相当。
- 代码、数学和推理能力:在数学相关基准测试中,DeepSeek-V3 达到了非长链推理(CoT)模型中的最佳性能,甚至在某些基准测试中超过了 o1-preview。在编程竞赛基准测试(如 LiveCodeBench)中,DeepSeek-V3 的表现也优于其他模型。
关键结论DeepSeek-V3 的主要贡献包括:
- 架构创新:引入无辅助损失的负载平衡策略和多 token 预测训练目标,提升了模型性能。
- 高效的预训练:通过 FP8 混合精度训练和算法、框架、硬件的协同设计,实现了高效的训练,降低了训练成本。
- 知识蒸馏:从 DeepSeek-R1 系列模型中蒸馏推理能力,显著提升了模型的推理性能。
- 性能表现:在多个基准测试中,DeepSeek-V3 的表现优于其他开源模型,并与领先的闭源模型相当。
限制与未来方向尽管 DeepSeek-V3 在性能和训练效率方面表现出色,但在部署方面仍存在一些限制,例如推荐的部署单元较大,可能对小型团队造成负担。未来,研究者们计划继续优化模型架构,扩大训练数据规模,并探索更全面的模型评估方法,以推动模型能力的进一步提升。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。

相关文章
更多>>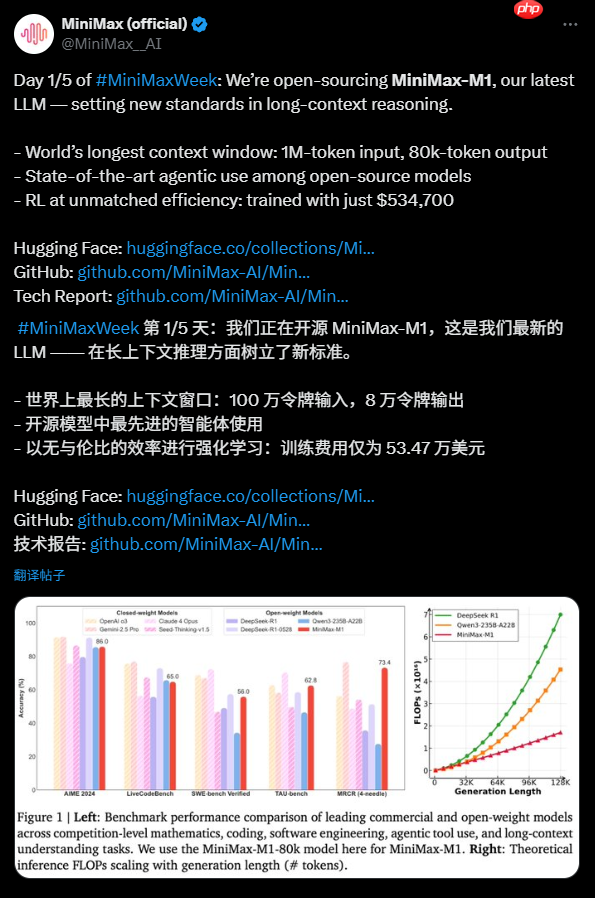










热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 仙剑玲珑排行榜下载大全-2023最好玩的仙剑玲珑前十名推荐
- 2023真武三国手游排行榜-真武三国手游2023排行榜前十名下载
- 心剑奇缘游戏排行-心剑奇缘所有版本-心剑奇缘游戏合集
- 灵域仙劫题材手游排行榜下载-有哪些好玩的灵域仙劫题材手机游戏推荐
- 仙境幻域游戏版本排行榜-仙境幻域游戏合集-2023仙境幻域游戏版本推荐
- 主宰领域手游排行-主宰领域免费版/单机版/破解版-主宰领域版本大全
- 2023破碎地牢手游排行榜-破碎地牢手游2023排行榜前十名下载
- 长恨天歌题材手游排行榜下载-有哪些好玩的长恨天歌题材手机游戏推荐
- 类似飞剑问仙的手游排行榜下载-有哪些好玩的类似飞剑问仙的手机游戏排行榜
- 类似魔月永恒的手游排行榜下载-有哪些好玩的类似魔月永恒的手机游戏排行榜
- 一剑主宰ios手游排行榜-一剑主宰手游大全-有什么类似一剑主宰的手游
- 烈火沙城系列版本排行-烈火沙城系列游戏有哪些版本-烈火沙城系列游戏破解版





